5 Steps To Implement DataOps Within Your Organization
Concise guide on how to implement DataOps. Described DataOps culture, Data Orchestration, Data Monitoring, Data Quality, automation tools for DataOps.
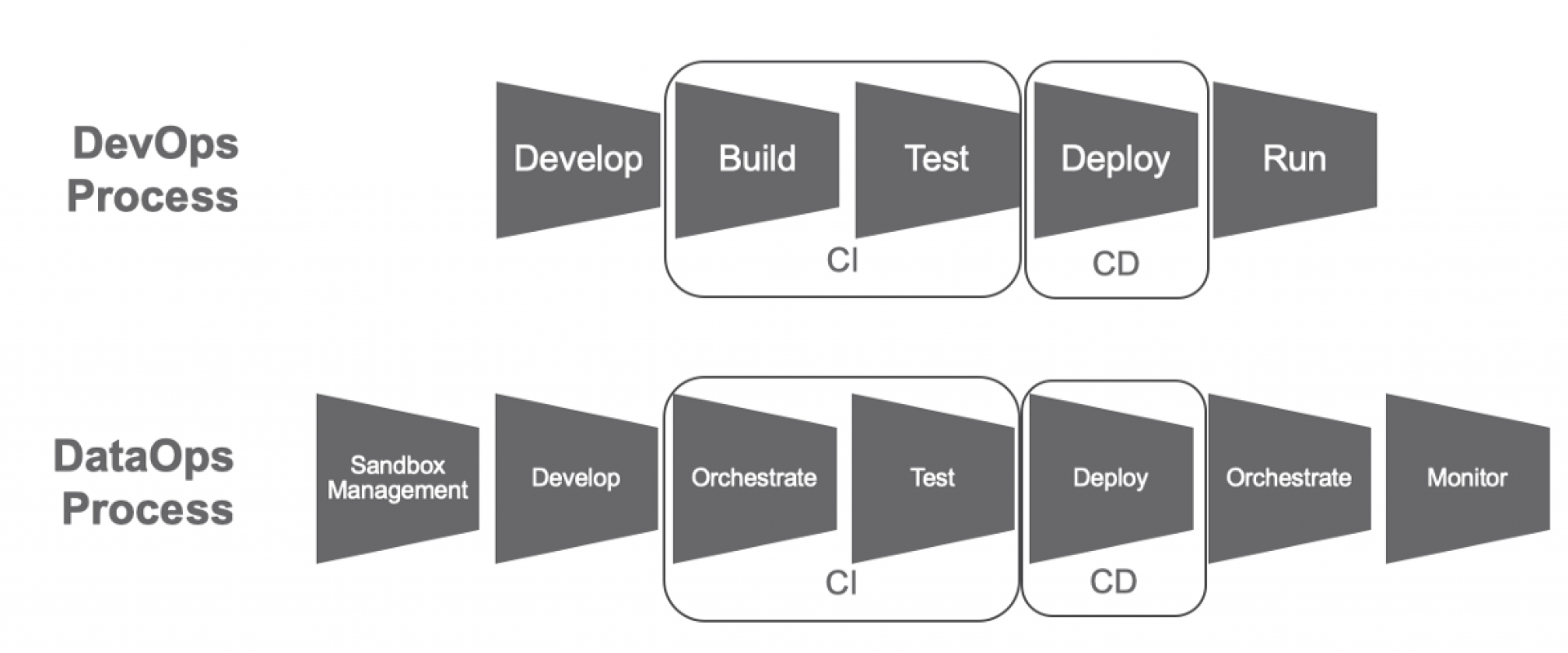
Successful DevOps Implementation is crucial for organizations looking to scale their business. But, what after you have implemented it successfully? Should you be technologically stagnant? The answer is definitely a “NO.”
Nearly after two decades of DevOps inception, we have access to newer forms of DevOps with enhanced quality and practices. One such form is known as DataOps. According to Gartner, DataOphs is a collaborative data management practice focused on improving the communication, integration, and automation of data flows between data managers and data consumers across an organization. In this blog, we have listed 5 major steps necessary for the successful implementation of DataOps.
Define the DataOps Culture
In any organization, different job roles have different said boundaries. A data project demands different types of resources ranging from developers and testers to business users and operation data executives. To implement DataOps successfully within your organization’s culture, you need to remove the wall of boundary. This can be achieved by
- Making the development teams understand their responsibility related to data quality issues in production environments
- Business users should take added responsibility to provide data transformation requirements
By performing the above two changes, you ensure that the developer involves business users and operation data stewards from the very beginning of the project.
Data Orchestration
Organizations have Petabytes of data. Manual management of moving or streaming thousands of data is both a time-consuming and error-prone task. Managing things like this will lead to stale data and loss of productivity. The goal of data orchestration is to automate the repetitive task of scheduling the execution of data. This will remove the unnecessary burdens from data engineers and support teams. Good data orchestration tools must have :
- Ability to orchestrate complex data pipelines
- Scalability to manage hundreds of data flows
- Intuitive graphical interface for data pipeline visualization
- Reusable components library
- Support for a variety of pipeline triggers
Data Monitoring
Data Monitoring is also referred to as “the first step towards Data Quality.” The idea is to catch potential data anomalies. Data monitoring can be implemented by collecting various metrics such as the number of processed records, ranges of numeric values or date columns, size of data in text, and the number of empty values. Each metric is used to calculate usual statistics data like mean, median, percentiles, and standard deviation.
With the help of the above information, we can analyze whether the new data is different from the past observed data. A team of data analytics and data scientists also leverage the collected data to quickly validate some hypotheses.
Data Quality
The primary goal of data quality is to automatically detect data corruption in the pipeline and try to contain it. This goal is achieved by using two main techniques :
- Business rules - Tests that run continuously in the production data pipeline ensuring data compliance with pre-defined requirements. It is one of the most precise techniques that need the most effort to ensure data integrity and quality.
- Anomaly detection - By tweaking a few of the thresholds to balance between precision and recall, we can use anomaly detection implemented with data monitoring for data quality enforcement.
Leverage Automation Tools for DataOps
DataOps is all about continuously integrating, deploying, testing, and monitoring data. Achieving these goals is not feasible without the help of proper automation tools. As such, organizations must acquire multiple software platforms for supporting DataOps, such as :
- Code versioning tool (Git)
- QA software for data test automation (Selenium)
- CI/CD software (Jenkins)
- Issue management software (Jenkins)
- Data catalog and data lineage (Google cloud/Azure)
Conclusion
Based on the fundamentals of DevOps and Agile, DataOps is sooner or later going to be an important data analytics methodology for enterprises. To be successful with DataOps, organizations need to adjust their culture, hire relevant skillset personnel, change their collaboration process, and leverage automation tools to assist with the processes. In this blog, we have highlighted 5 key areas where you need to focus in order to strategically implement DataOps within your organization. What’s your thought about DataOps? Let us know in the comments below.
Relevant Blogs:
Test Automation vs. Autonomous
Testing CI/CD for Cloud-Native Applications
How To Boost Your In-house Enterprise DevOps Talent?
GitOps: What Is It and How Does It Work?
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post