An Introduction to Data Mesh
Let’s take a closer look at the concept and review the data mesh architecture to understand its benefits better.
As more and more teams have started to look for solutions that can help them unlock the full potential of their systems and people, decentralized architectures have started to become more and more popular. Whether it’s cryptocurrencies, microservices, or Git, decentralization has proven to be an effective method of dealing with centralized bottlenecks. Along the same lines, one approach to decentralizing control of data is using a data mesh. But what is it, and how can it help? Let’s take a closer look at the concept and go over the data mesh architecture to better understand its benefits.
Data Challenges in Enterprises
It’s no secret that organizations have come quite a long way in their data journey. However, they still have their set of challenges that prevents them from leveraging the full benefits of data. These challenges include:
Trustworthiness
The traceability, quality, and observability of data demand robust implementation. It’s important to ask yourself a few important, difficult questions. These include:
- Can you trust the data?
- Is your data file complete?
- Do you have the latest file?
- Is your data source correct?
Agility
Change is the only constant thing, and that’s true for large enterprises, too. It’s very difficult for data estates to keep up with these changes, which come in the way of enterprise agility. Take report generation, for instance – it takes weeks to do that, and that’s quite a big time frame in today’s fast-paced world.
Skills
To keep up with data, the entire workforce should have specialized skills. This is because maintaining data can become quite expensive and with a lack of skills, bottlenecks are bound to be very frequent.
Productivity
Productivity is another data challenge. Both business and data analysts spend up to 30-40% of their time looking for the correct dataset. Similarly, data engineers spend most of their time figuring out how to create a uniform dataset using disparate sources.
Ownership
Establishing dataset ownership is also a challenge. It’s hard to determine the owner and who can be trusted enough to declare the dataset trustworthy. In most cases, the team that owns the data platform takes ownership of the data, even though it might not understand it.
Discoverability
Only a few organizations have been able to leverage their data estate and set up a data marketplace where their consumers can explore different datasets and understand the ones they wish to use.
What Is Data Mesh?
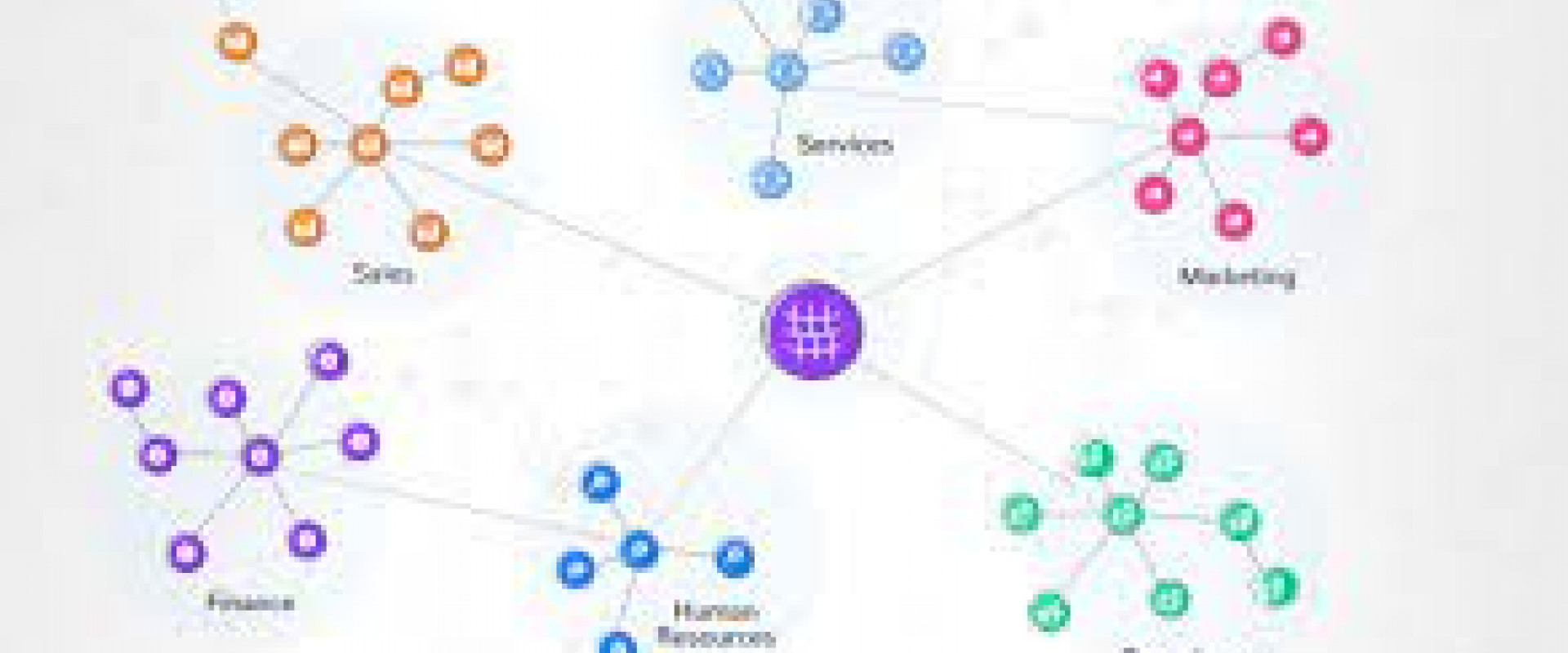
An overview of a data mesh
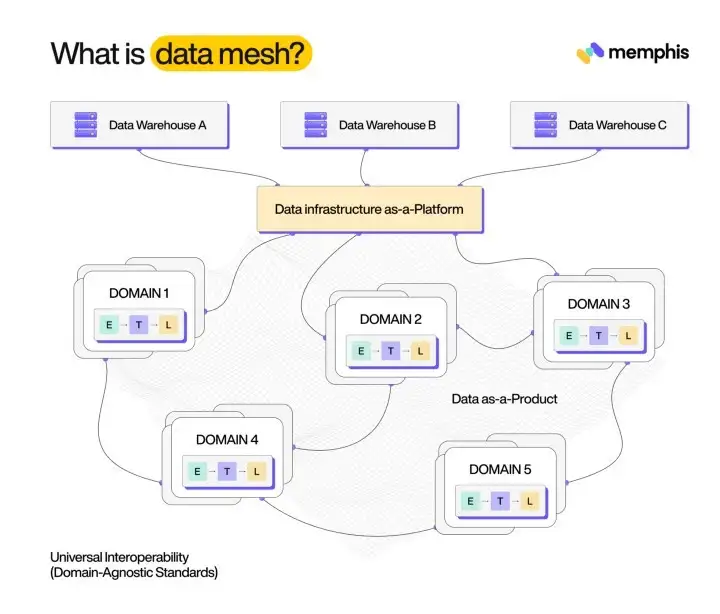
A data mesh can be best understood as a practice or concept used to manage a large amount of data spread across a decentralized or distributed network. It can also refer to a platform responsible for this function, or even both. As companies become increasingly dependent on their ability to store volumes of data and distribute it through data pipelines and leverage from it, it’s important to create an effective schema for using that data. This is where a data mesh comes in.
The idea behind a data mesh is that introducing more technology won’t help to solve the data challenges that companies face today. Instead, the only way to face those challenges is to reorganize the tools, processes, and people involved. A data mesh essentially creates a replicable method of managing different data sources across the company’s ecosystem and makes it more discoverable. At the same, it ensures consumers faster, more secure, and more efficient access to data.
A data mesh includes numerous benefits. These include:
- Allows for decentralized data operations which improve business agility, scalability, and time-to-market.
- Organizations that adopt the data mesh architecture prevent being locked into one data product or platform.
- Adopts a self-service model that ensures easy access to a centralized infrastructure. This allows for faster SQL queries and data access.
- Since it decentralizes data ownership, it ensures transparency across teams. (In comparison, centralized data ownership makes data teams heavily dependent upon).
Data Mesh Architecture Components
The data mesh architecture involves four main components. Let’s go over them one by one.
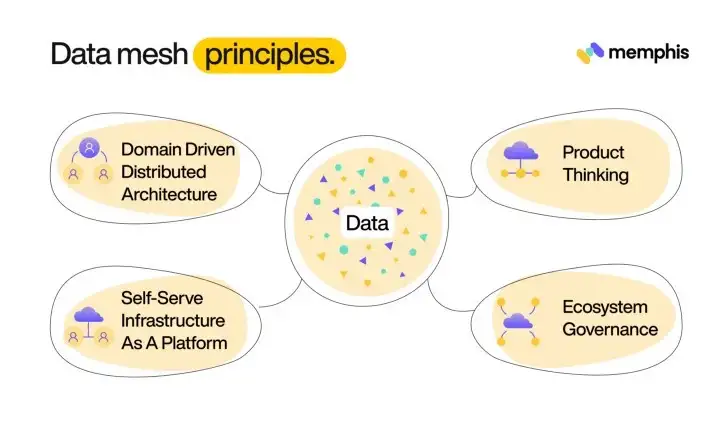 4 data mesh principles (Source)
4 data mesh principles (Source)
Decentralized Data Ownership
This architecture component mainly revolves around the people involved and calls for the remodelling of the monolith data structure by decentralizing analytical data and realigning its ownership from a central team to a domain team.
In a data mesh, a domain team that’s extremely familiar with the data asset is responsible for curating it, ensuring high-quality data administration and governance. In contrast, in a data warehouse antipattern, a generalist team is responsible for managing all the data of the organization and is usually focused on the technical aspect of the data warehouse instead of the quality of the data.
So organizations implementing a data mesh must define which data set is owned by which domain team. In addition to that, all the teams should be quick to make changes to maintain their mesh’s data quality. By making domain-centric accountability possible, decentralized data ownership solves many problems related to agility, ownership, and productivity.
For instance, organizations take a while to respond to the market since changes have to be made to many IT systems to make any business change. This is why unaligned priorities and poor coordination across the team hinder enterprise agility. Considering the rapid growth in data sources and the proliferating business use cases, central teams have become nothing more than bottlenecks. However, going from a monolithic architecture to domain-driven microservices has made operational systems more agile. And a data mesh can do the same for analytical data.
Data consumers usually spend their time finding the data owner, determining its traceability, and interpreting its meaning. As a result, the overall productivity of teams is reduced. However, decentralization brings both the analytical and operational world closer and establishes traceability, ownership, and a clear interpretation, thus improving the teams’ turnaround times.
And finally, ownership; in most cases, data owners aren’t known, making the IT teams responsible for the ETL the owners of the data. Central IT teams often act as intermediaries – they pass consumer requests to producers and aren’t considered owners because they don’t produce the data and neither do they understand it. Realigning the ownership of analytical data to the right domains can solve the problem since these domains are the producers of data and can understand it, too.
Data as a Product
With domains identified and ownership established, the next step is to stop thinking of analytical data as an asset that must be stored and instead think of it as a product that must be served. Teams responsible for a data mesh publish data so that other teams, i.e., their internal customers, can benefit from it.
This is why domains need to stop considering analytical data as a by-product of business operations and think of it as a first-class product complete with dedicated owners that are responsible for its usability, discoverability, uptime, and quality and treat it just like any other business service. As such, they should also apply the different product development aspects to make it customer-focused, reliable, useful, and valuable. You can think of data products published by the teams responsible for a data mesh as microservices; the only difference is that data is on offer.
Thinking of data as a product solves problems related to productivity, agility, discoverability, and trustworthiness. The productivity of a data consumer automatically increases as trustworthiness, discoverability, and agility come into the equation. Let’s see how.
A data product is essentially an autonomous unit with its own release cycles and feature roadmap. This means that data teams don’t need to wait for a central team to provide some environment or data so that they can start working. In turn, establishing traceability and authenticity hardly takes time. Similarly, reworking to align the SLOs (service level objectives) of the input dataset with that of the use case takes relatively less time.
And with data ownership assigned to domains, the product owner (of the data) is responsible for the data product. This means that the product owner should make sure that the data product’s security, traceability, and quality are maintained and also reported via SLOs and the right metrics.
And finally, by thinking of data as a product, each product is self-explanatory and is advertised and catalogued on the organization’s data marketplaces. The relevant documentation outlines different usability topics and explains the relationship with other SLOs and data products. As a result, consumers get to enjoy full visibility of the data product, which, in turn, allows them to make a well-informed decision about its use.
Self-Serve Platform
Even though thinking of data as a product has numerous benefits, it might end up increasing the overall operation cost because it involves many small but highly skilled teams and numerous independent infrastructures. Plus, if these highly skilled teams aren’t properly optimized, the operating cost will go up further. This is where the third component of the data mesh architecture comes into play – a self-serve platform.
Although a data mesh revolves around the idea of decentralized data management, one of its most important aspects is a centralized location or a central data infrastructure that can facilitate the data product lifecycle, where all the members of the organization can easily find the datasets they require. This central infrastructure should support tenancy so that it facilitates autonomy. It should also be self-serve, and provide multiple out-of-the-box tools.
Historical, as well as real-time, should be available, and there should be some automated way of accessing data. While there are no plug-and-play tools that fulfil this principle, it can be accomplished via a wiki, a UI, or an API.
The important thing is that self-serve tools should be thoughtfully built and must reduce the cognitive load on the data product teams. They should also bring abstraction over the lower-level technical components to allow for data product standardization and faster development. Another important part of self-service is data product management, which includes removing, adding, and updating data products. Plus, management and entry should be as easy as possible to make usage easy.
Just like other components, the self-serve platform also solves several problems related to skills, cost of ownership, and agility. Since a self-serve platform takes away technical complexity, there’s less need for specialists and generalists are enough to serve the purpose. As a result, there’s no need to invest in a highly skilled team. The cost of ownership also reduces in terms of the infrastructure, since it’s centrally provisioned. And finally, autonomous data product teams can directly use the self-service platform; they don’t need to rely on the central infrastructure team to provide them with infrastructure resources and data. This speeds up the development cycle.
Federated Computational Governance
The three data mesh architecture principles discussed above solve most of the data challenges faced by organizations. However, since most data products operate across different domains, how can you harmonize data? The answer to this lies in the last architecture component: federated computational government, which is a big change from how traditional central governance is enforced. The former changes the way teams are organized and the way the infrastructure supports governance. In federated governance, a data product owner manages different aspects such as local access policies, data modelling, data quality, etc. This is a big shift from implementing canonical data to models to smaller ones specifically built to meet the needs of the data product.
Governance should be divided into two: local and global governance. The former is local to the data product, defines the local processes, frameworks, and governance policies, and is responsible for their implementation and adherence. This is a step away from central governing bodies that created policies and were responsible for validation and adherence.
Meanwhile, global governance involves a cross-functional body with experts in different specializations such as technology, legal, security, and infrastructure and is responsible for formulating policies. The local governing body is responsible for implementation as well as constant adherence.
To sum up, with federated governance applied to your data mesh, teams can always use data available to them from different domains.
All these four principles are important to implement a data mesh in an organization. Of course, the degree of implementation can differ, but each principle has its benefits and overcomes the drawbacks of others. Just keep in mind that the bigger the mesh, the more value you can generate from the data.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, DataOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
10 Ways To Keep Your Java Application Safe and Secure
MSP Cybersecurity: What You Should Know
From Zero Trust To Secure Access: The Evolution of Cloud Security
The Future of Cloud Security: Trends and Predictions
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post