Enhancing Search Engine Efficiency With Elasticsearch Aliases
In this article, the reader will learn more about optimizing search performance and scalability with alias-based index management.
Elasticsearch is renowned for its robust search capabilities, making it a popular choice for building high-performance search engines. One of the key features that contribute to its efficiency is the use of aliases. Elasticsearch aliases provide a powerful mechanism for optimizing search operations, improving query performance, and enabling dynamic index management. In this article, we will explore how aliases can be leveraged to create an efficient search engine in Elasticsearch and demonstrate their practical usage through an architecture diagram and examples.
What Are Aliases?
Aliases in Elasticsearch are secondary names or labels associated with one or more indexes. They act as a pointer or reference to the actual index, allowing you to interact with the index using multiple names. An alias abstracts the underlying index name, providing flexibility and decoupling between applications and indexes.
Benefits of Using Aliases in Elasticsearch
Aliases in Elasticsearch provide a range of benefits that enhance index management, deployment strategies, search efficiency, and data organization. Let's explore the advantages of using aliases in more detail:
1. Index Abstraction: Aliases allow the abstract of the underlying index names by using user-defined names. This abstraction shields the application from changes in index names, making it easier to switch or update indexes without modifying the application code. By using aliases, the application can refer to indexes using consistent, meaningful names that remain unchanged even when the underlying index changes.
2. Index Management: Aliases simplify index management tasks. When creating a new index or replacing an existing one, it can update the alias to point to the new index. This approach enables seamless transitions and reduces the impact on application configurations. Instead of updating the application code with new index names, it only needs to modify the alias, making index updates more manageable and less error-prone.
3. Blue-Green Deployments: Aliases are particularly useful in blue-green deployment strategies. In such strategies, it maintains two sets of indexes: the "blue" set represents the current production version, while the "green" set represents the new version being deployed. By assigning aliases to different versions of indexes, it can seamlessly switch traffic from the old version to the new version by updating the alias. This process ensures zero downtime during deployments and enables easy rollback if necessary.
4. Index Rollover: Elasticsearch's index rollover feature allows it to automatically create new indexes based on defined criteria, such as size or time. Aliases can be used to consistently reference the latest active index, simplifying queries and eliminating the need to update index names in the application. With aliases, it can query the alias instead of referencing specific index names, ensuring that the application always works with the latest data without requiring manual intervention.
5. Data Partitioning: Aliases enable efficient data partitioning across multiple indexes based on specific criteria by associating aliases with subsets of indexes that share common characteristics, such as time ranges or categories, which can narrow down the search space and improve search performance. For example, it can create aliases that include only documents from a specific time range, allowing it to search or aggregate data within that partition more efficiently.
6. Filtering and Routing: Aliases can be associated with filters or routing values, providing additional flexibility in search operations. By defining filters within aliases, it can perform searches or aggregations on subsets of documents that match specific criteria. This enables to focus search operations on relevant subsets of data, improving search efficiency and reducing unnecessary data processing. Similarly, routing values associated with aliases allow direct search queries to specific indexes based on predefined rules, further optimizing search performance.
Scenario
To better understand aliases in action, let's consider a practical example of an e-commerce platform that handles product data and uses a search microservice for searching product information. The platform maintains an index named "index1" to store product information, as shown in Figure 1. Now, let's assume we want to introduce versioning, which involves indexing new product information to make it available for customer searches. The goal is to seamlessly transition to the new version without any disruptions to the application.
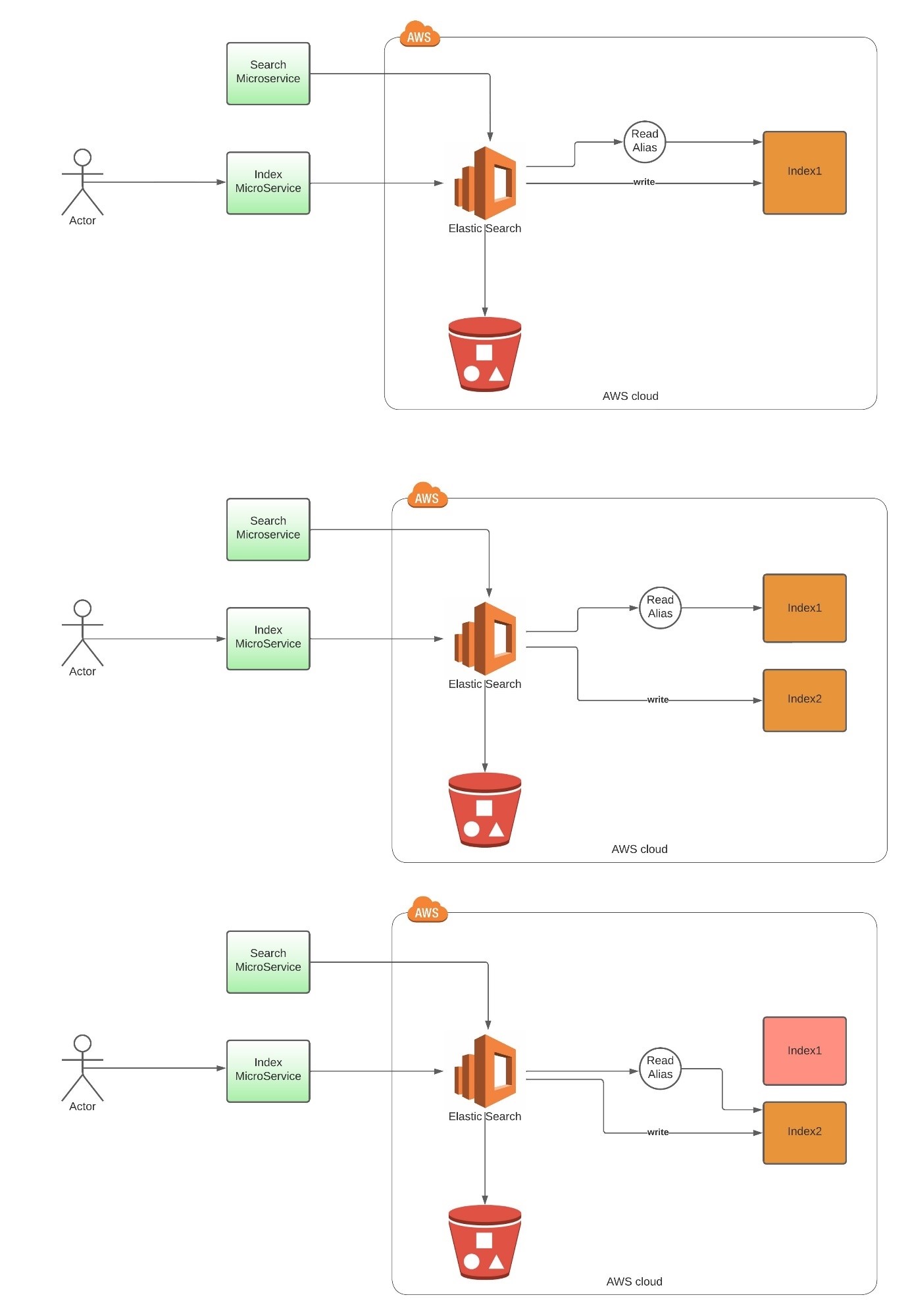
Figure 1: Swapping of Alias between the indexes
Step 1: Initial Index Setup
The e-commerce platform begins with an index named "index1," which holds the existing product data.
Step 2: Creating an Alias
To ensure a smooth transition, the platform creates an alias called "readAlias" and associates it with the "index1" index. This alias acts as the primary reference point for the application, abstracting the underlying index name.
Step 3: Introducing a New Index Version
To accommodate updates and modifications, a new version of the index, "index2," is created. This new version will store the updated product information. While the search application, upon running and reads the data from Index1 through readAlias.
Step 4: Updating the Alias
To seamlessly switch to the new index version, the platform updates the alias "readAlias" to point to the "index2" index. This change ensures that the application can interact with the new index without requiring any modifications to the existing codebase.
Step 5: Dropping the Older Index
Once the alias is successfully updated, the platform can safely drop the older index, "index1," as it is no longer actively used.
By updating the alias, the application can seamlessly interact with the new index without any code modifications. Additionally, it can employ filtering or routing techniques through aliases to perform specific operations on subsets of products based on categories, availability, or other criteria.
Create an Alias in Elasticsearch Using the Elasticsearch Rest API
PUT /_aliases { "actions": [ { "add": { "index": "index1", "alias": "readAlias" } } ]}
Updating the Alias and Dropping the Older Index
To switch the alias to the new index version and drop the older index, we can perform multiple actions within a single _aliases operation. The following command removes "index1" from the "readAlias" alias and adds "index2" to it:
POST _aliases { "actions": [ { "remove": { "index": "index1", "alias": "readAlias" } }, { "add": { "index": "index2", "alias": " readAlias" } } ]}
With these operations, the alias "readAlias" now points to the "index2" version, effectively transitioning to the new product data.
Elasticsearch Aliases in a Spring Boot Application
To use Elasticsearch aliases in a Spring Boot application,
first, configure the Elasticsearch connection properties. Then, create an
Elasticsearch entity class and annotate it with mapping annotations. Next,
define a repository interface that extends the appropriate Spring Data
Elasticsearch interface. Programmatically create aliases using the ElasticsearchOperations bean
and AliasActions. Finally,
perform search and CRUD operations using the alias by invoking methods from the
repository interface. With these steps, you can seamlessly utilize
Elasticsearch aliases in your Spring Boot application, improving index
management and search functionality.
@Repository
public interface ProductRepository extends ElasticsearchRepository
@Autowired
private ElasticsearchOperations elasticsearchOperations;
@PostConstruct
public void createAliases() {
String indexV1 = "index1";
String indexV2 = "index2";
IndexCoordinates indexCoordinatesV1 = IndexCoordinates.of(indexV1);
IndexCoordinates indexCoordinatesV2 = IndexCoordinates.of(indexV2);
AliasActions aliasActions = new AliasActions();
// Creating an alias for indexV1
aliasActions.add(
AliasAction.add()
.alias("readAlias")
.index(indexCoordinatesV1.getIndexName())
);
// Creating an alias for indexV2
aliasActions.add(
AliasAction.add()
.alias("readAlias")
.index(indexCoordinatesV2.getIndexName())
);
// Applying the alias actions
elasticsearchOperations.indexOps(Product.class).aliases(aliasActions);
}
}
In this example, the createAliases() method
is annotated with @PostConstruct, ensuring
that the aliases are created when the application starts up. It uses the AliasActions class
to define the alias actions, including adding the alias "readAlias"
for both "index1" and "index2" indexes.
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
public
List
return productRepository.findByName(query);
}
// Other service methods for CRUD operations
}
In the ProductService class,
we can invoke methods from the ProductRepository to
perform search operations based on the "readAlias" alias. The Spring
Data Elasticsearch repository will route the queries to the appropriate index
based on the alias configuration.
Conclusion
Elasticsearch aliases provide a valuable tool for managing indexes, enabling seamless transitions, versioning, and efficient data retrieval in e-commerce platforms. By utilizing aliases, e-commerce businesses can ensure uninterrupted service, leverage search microservices, and enhance their overall data management capabilities. Embracing aliases empowers organizations to evolve their product indexes while maintaining a stable and performant application environment.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, DataOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
Container Security: Don't Let Your Guard Down
Data Warehouses: The Undying Titans of Information Storage
Seven AWS Data Stores You Can Use To Store and Manage Your Data With Ease
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post