Getting Started With Apache Cassandra
In this hands-on primer on the powerful open-source NoSQL database Apache Cassandra, our discussion includes the CAP theorem and how to structure data.
Apache Cassandra® is a distributed NoSQL database that is used by the vast majority of Fortune 100 companies. By helping companies like Apple, Facebook, and Netflix process large volumes of fast-moving data in a reliable, scalable way, Cassandra has become essential for the mission-critical features we rely on today.
In this post, we will:
- Discuss NoSQL databases and the power of purpose-built databases
- Introduce Cassandra, a peer-to-peer database
- Explain the consistency, availability, and partition tolerance (CAP) theorem (i.e. the law of distributed systems)
- Demonstrate how to structure data with tables and partitions
- Share hands-on exercises you can complete on GitHub
From SQL to NoSQL: Why NoSQL Was Invented
Relational database management systems (RDBMS) dominated the market for decades. Then, with the rise of Big Tech like Apple, Facebook, and Instagram, the global datasphere skyrocketed 15-fold in the last decade. RDBMS simply weren’t ready to cope with the new data volume or new performance requirements.
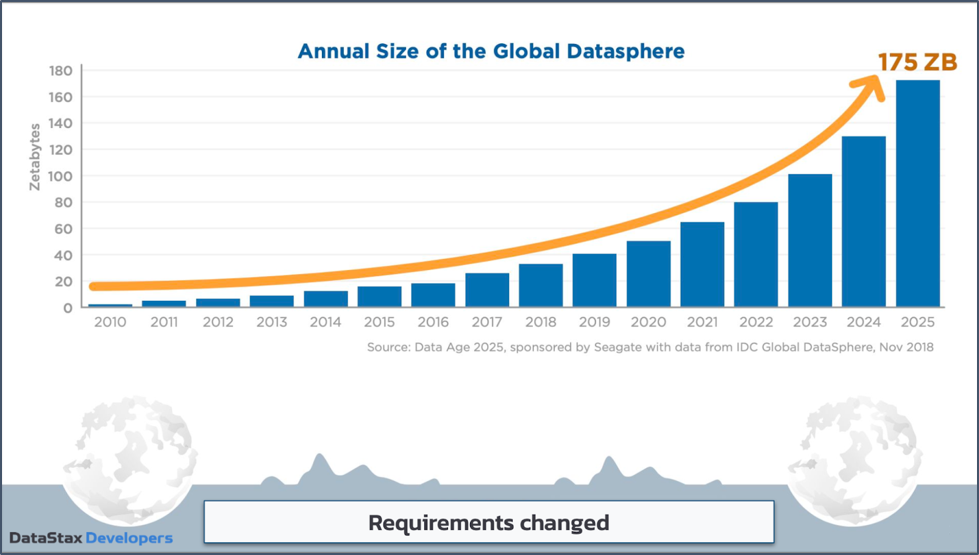
Figure 1. Skyrocketing data needs.
NoSQL was not only invented to cope with massive volumes of data but also to tackle the challenge of both velocity (speed requirements) and variety (all the different types of data and data relations in the market).
Other than tabular databases like Cassandra, we’ve also seen the rise of other types of NoSQL databases, such as:
- Time-series databases (e.g. Prometheus)
- Document databases (e.g. MongoDB)
- Graph databases (e.g. DataStax Graph)
- Ledger databases (e.g. Amazon QLDB)
- Key/value databases (e.g. Redis)
What Makes Cassandra So Powerful?
Known for its performance at scale, Cassandra is regarded as the Lamborghini of the NoSQL database world: it is essentially infinitely scalable. There is no leader node, and Cassandra is a peer-to-peer system.
For example, at Netflix, Cassandra runs 30 million ops/second on its most active single cluster and 98% of streaming data is stored on Cassandra. Apple runs 160,000+ Cassandra instances with thousands of clusters.
There are eight features that make Cassandra powerful:
1. Big data ready: Partitioning over distributed architecture makes the database capable of handling data of any size — at petabyte scale. Need more volume? Add more nodes.
2. Read-write performance: A single node is very performant, but a cluster with multiple nodes and data centers brings throughput to the next level. Decentralization (leaderless architecture) means that every node can deal with any request, read or write.
3. Linear scalability: There are no limitations on volume or velocity and no overhead on new nodes. Cassandra scales with your needs.
4. Highest availability: Theoretically, you can achieve 100% uptime thanks to replication, decentralization, and topology-aware placement strategy.
5. Self-healing and automation: Operations for a huge cluster can be exhausting. Cassandra clusters alleviate a lot of headaches because they are smart — able to scale, change data replacement, and recover — all automatically.
6. Geographical distribution: Multi-data center deployments grant an exceptional capability for disaster tolerance while keeping your data close to your clients, wherever they are in the world.
7. Platform agnostic: Cassandra is not bound to any platform or service provider, which enables you to build hybrid-cloud and multi-cloud solutions with ease.
8. Vendor independent: Cassandra doesn’t belong to any of the commercial vendors but is offered by the non-profit, open-source Apache Software Foundation, ensuring both open availability and continued development.
How Does Cassandra Work?
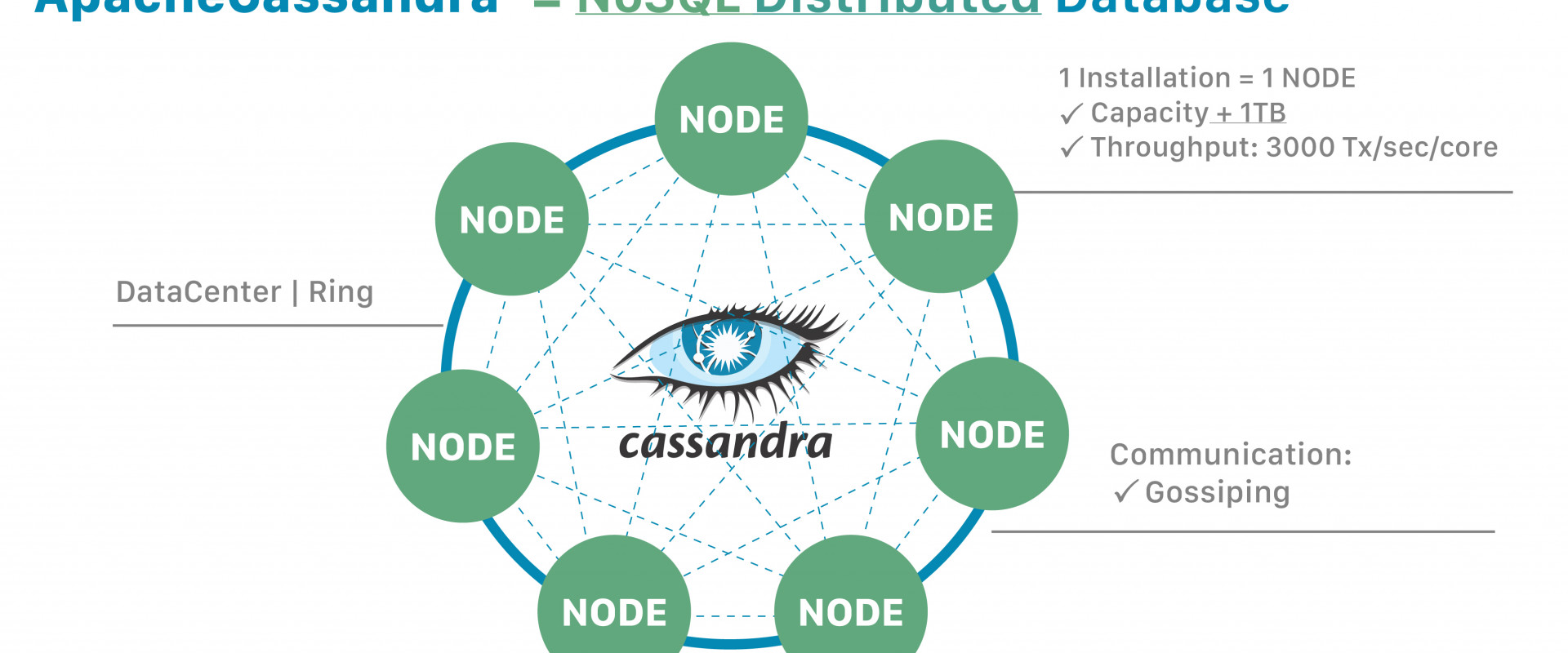
In Cassandra, all servers are created equal. Unlike traditional architecture, where there is a leader server for write/read and follower servers for read-only, leading to a single point of failure, Cassandra’s leader-less (peer-to-peer) architecture distributes data across multiple nodes within clusters (also known as data centers or rings).
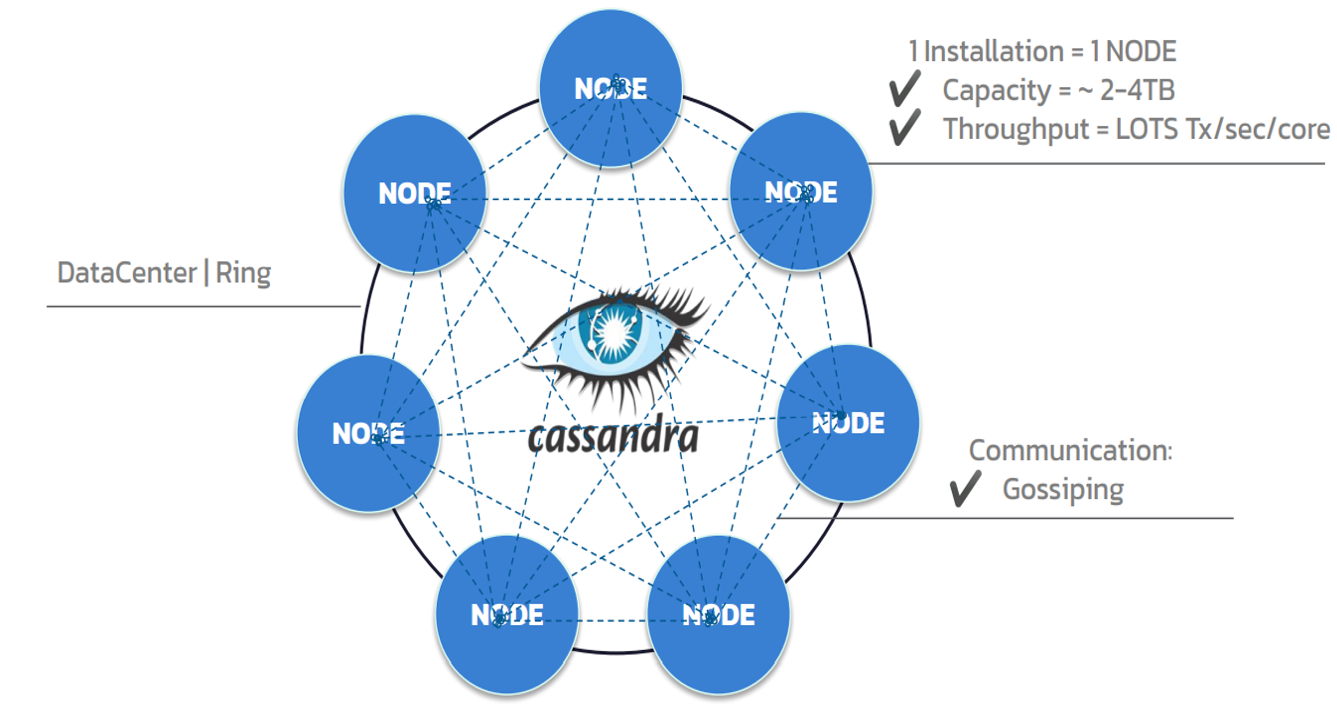
Figure 2. Apache Cassandra structure.
A node represents a single instance of Cassandra, and each node stores a few terabytes of data. Nodes “gossip” or exchange state information about themselves and other nodes across the cluster for data consistency. When one node fails, the application contacts another node, ensuring 100% uptime.
In Cassandra, data is replicated. The replication factor (RF) represents the number of nodes used to store your data. If RF = 1, every partition is stored on one node. If RF = 2, then every partition is stored on two nodes, and so on. The industry standard is a replication factor of three, though there are cases that call for using more or fewer nodes.
The CAP theorem: is Cassandra AP or CP?
The famous “CAP” theorem states that a distributed database system can only guarantee two out of these three characteristics in case of a failure scenario: Consistency, Availability, and Partition Tolerance:
1. Availability: This basically means “uptime.” If servers fail but still give a response, then your system is available.
2. Consistency: This means “no stale data.” A query returns the most recent value. If one of the servers returns outdated information, then your system is inconsistent.
3. Partition Tolerance: This is the ability of a distributed system to survive “network partitioning.” Network partitioning means part of the servers cannot reach the second part.
Any database system, including Cassandra, has to guarantee partition tolerance: It must continue to function during data losses or system failures. To achieve partition tolerance, databases have to either prioritize consistency over availability “CP,” or availability over consistency or “AP”.
Cassandra is usually described as an “AP” system, meaning it errs on the side of ensuring data availability even if this means sacrificing consistency. But that’s not the whole picture. Cassandra is consistently configurable: You can set the consistency level you require and tune it to be more AP or CP according to your use case.
How Does Cassandra Structure and Distribute Data?
Cassandra’s innate architecture can handle and distribute massive amounts of data across thousands of servers without experiencing downtime. Each Cassandra node and even each Cassandra driver knows data allocation in a cluster (it’s called token-aware), so your application can contact any server and receive fast answers.
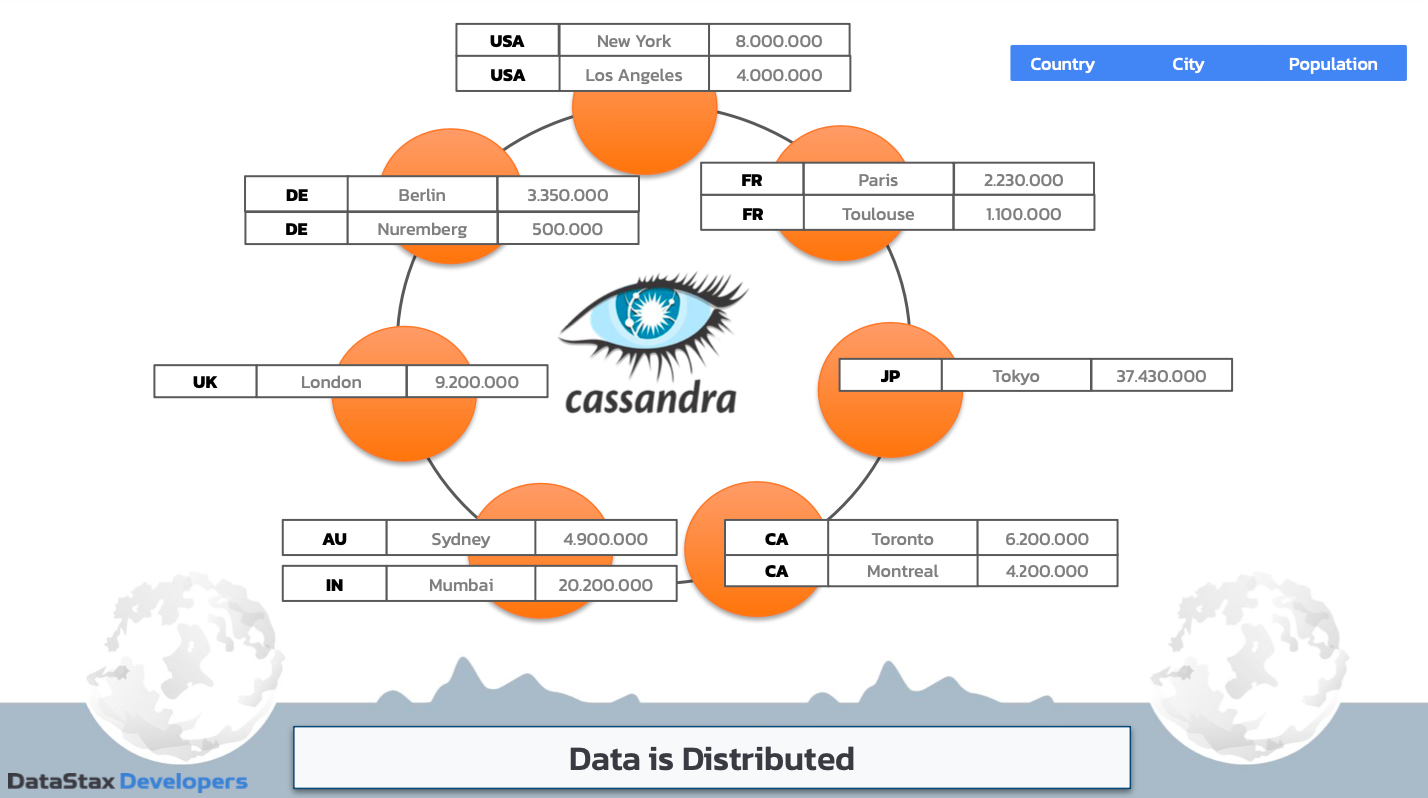
- Keyspace: A container of data, similar to a schema, which contains several tables
- Table: A set of columns, primary key, and rows storing data in partitions
- Partition: A group of rows together with the same partition token (a base unit of access in Cassandra)
- Row: A single, structured data item in a table
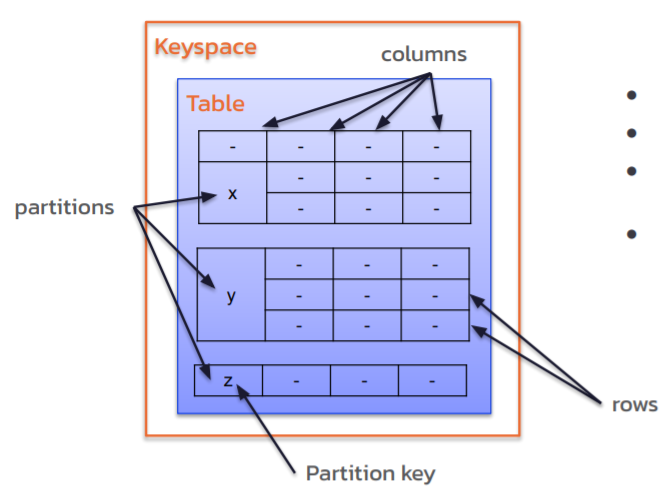
Figure 4. Overall data structure on Cassandra.
Cassandra stores data in partitions, representing a set of rows in a table across a cluster. Each row contains a partition key – one or more columns that are hashed to determine how data is distributed across the nodes in the cluster.
Why partitioning? Because this makes scaling so much easier! Big data doesn’t fit in a single server. Instead, it’s split into chunks that are easily spread over dozens, hundreds, or even thousands of servers, adding more if needed.
Once you set a partition key for your table, a partitioner transforms the value in the partition key to tokens (also called hashing) and assigns every node with a range of data called a token range.
Cassandra then distributes each row of data across the cluster by the token value automatically. If you need to scale up, just add a new node, and your data gets redistributed according to the new token range assignments. On the flip side, you can also scale down hassle-free.
Data architects need to know how to create a partition that returns queries accurately and quickly before they create a data model. Once you’ve set a primary key for your table, it cannot be changed. Instead, you’ll need to create a new table and migrate all the new data.
We ZippyOPS, Provide consulting, implementation, and management services on DevOps, DevSecOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
Relevant Blogs:
Data Platform: The Successful Paths
Types of system hardening OS Hardening: 10 Best Practice
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post