Liquibase on Kubernetes

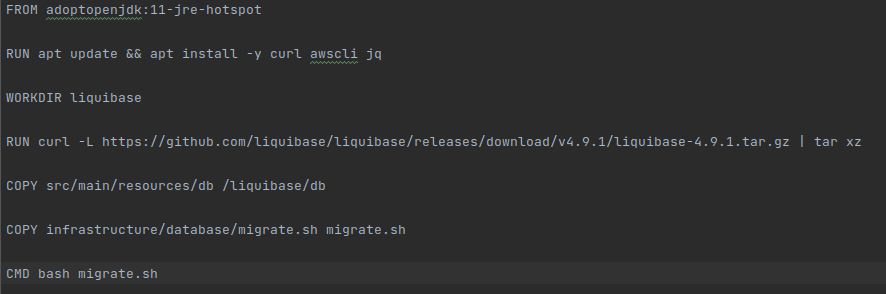
Once we have created our
independent dockerfile for the init container, we need to create the file, bash
in our case, that will be executed from start to finish in our Init Container.
In our example, in order to run the liquibase command that updates the bd, we
need to extract all the necessary information using the secret arn.
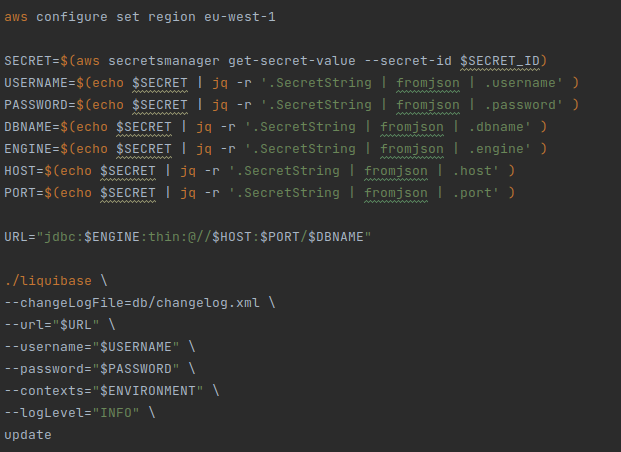
Here is a very important point to
make. If we already have our service in production and running, and what we are
going to do is simply to change the migration system to be used by this method,
we must take into account the following: the value of the changeLogFile parameter must be exactly the same that appears in
the FILENAME field
of the DATABASECHANGELOG table.
Otherwise, it would identify the changelog as a different one and proceed to apply it from the beginning, with all the problems that this entails (from a simple error in creating an existing table, to an overwriting of our data in production).
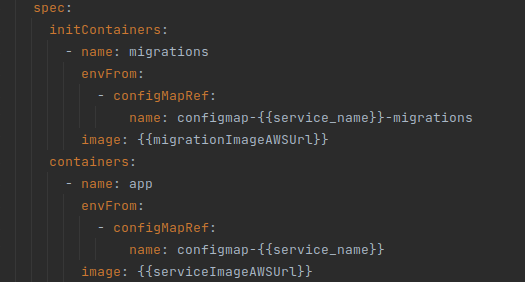
Now, we must configure the k8s
YAML files to use our new dockerfile as Init Container. Assuming that we have our service
configured with the name “app”. The name we have decided to put for our init
container is “migrations”, and the configuration, would be the one that can be
seen below:
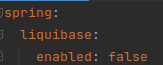
With this, we should be able to deploy with Init Containers. In our case, we had to disable the migrations when starting the app in Spring, to avoid the “app” containers trying to launch the migrations again, after the init Container. In this example, it is as simple as indicating in the application.yml that liquibase is not activated:
And with this, we should have our
init container running to launch the migrations before raising the containers
with our application.
As a note, I would like to comment that to execute the e2e tests, we can
configure our application.yml so that in the test profile it executes the liquibase
migrations when starting the app for the database that we use in this
environment, H2 in our case.
Conclusions
I have left some time since I
wrote this article before writing the conclusions, to verify our hypothesis.
After some time with this working, we have seen that sometimes the init
container can also fail, for various reasons, unrelated to the deployment
process itself. But it is true that this solution has minimized the database
locking problems when applying migrations in a very significant way.
Therefore, despite not being a foolproof method, it is a huge improvement over
the previous state of our microservice in Kubernetes. So if your microservice
manages migrations with Liquibase, I recommend using Init Containers to perform
them.
We are still working to find the solution to those exceptional cases where a
database crash occurs when running migrations.
The nice thing about having
abstracted migration management in a bash file running in the init container is
that we have control over Liquibase. We have found some commands that allow us
to list-locks and release-locks. So for the moment, we have created a rule that reads the locks
and if it is more than 15 minutes since the last active lock, we assume that
the last init container has been corrupted and we proceed to release the lock
using the release-locks command.
At the moment, this is our approach, and it is working better than the initial situation. I hope you find this article helpful and feel free to leave feedback and/or alternative solutions to the same problem in the comments of this post.
We ZippyOPS, Provide consulting, implementation, and management services on DevOps, DevSecOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
Relevant Blogs:
Kubernetes-Native Inner Loop Development With Quarkus
Dockerizing a MERN Stack Web Application
Secure Kubernetes With Kubescape
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post