Release Management for Microservices: Multi vs. Monorepos
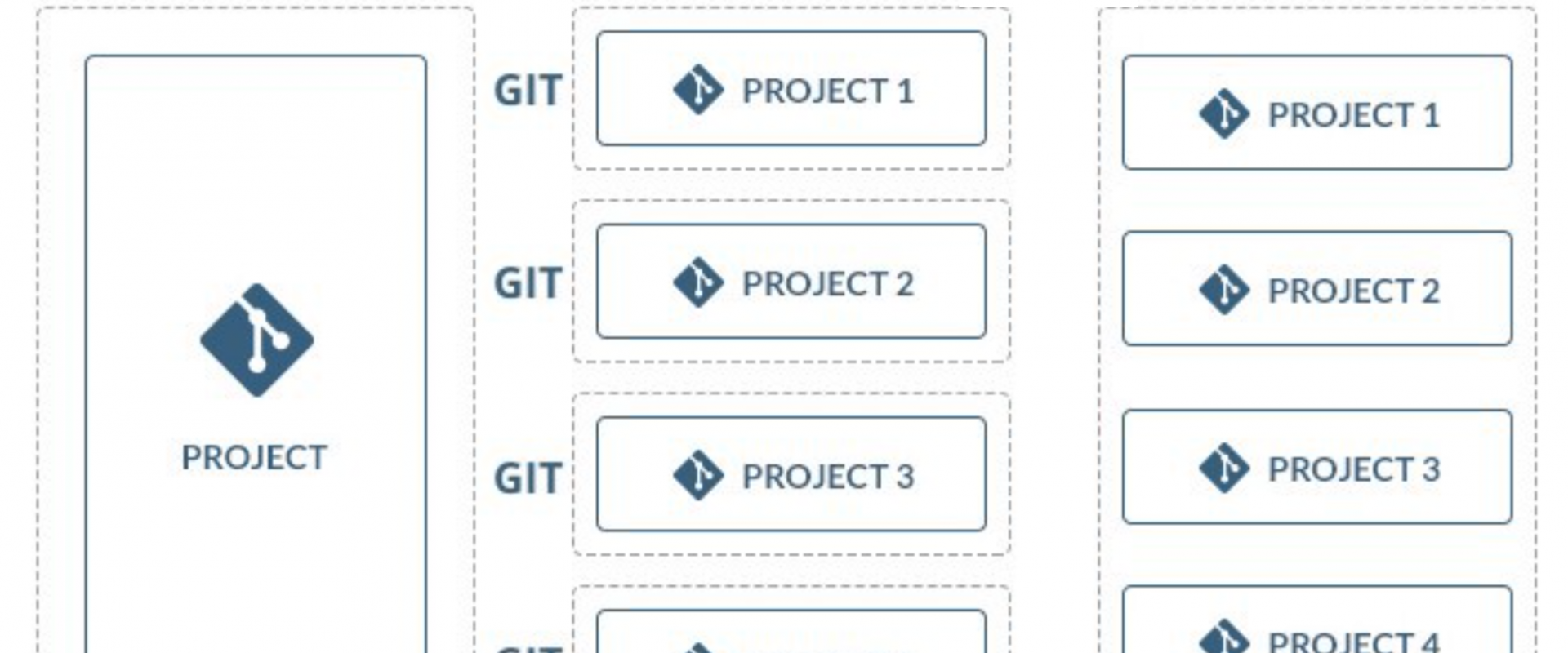
Deployments for microservice applications.
Imagine a microservice application consisting of dozens of continuously-deployed autonomous services. Each of the application’s constellation of services has its own repository, with a different versioning scheme and a different team continually shipping new versions.
Riddle me this: How can I tell the (whole) application’s version? Being that the change history is scattered among dozens of repositories, what’s the most efficient approach to keeping track of changes? And how do we manage application releases?
Any team using microservice architectures, including ours at Semaphore, must deal with these questions. In this article, I’d like to look at a couple different ways to answer them.
A Common Approach: One Microservice, One Repository
The most common way to start out with a microservice architecture application is to use the multirepo approach:
1. The design is broken up into microservices.
2. A separate repository is created for each microservice (where the “multi” in multirepo comes from).
3. Each repository has an independent CI/CD pipeline to continuously deploy the microservice to production.
Let’s call this fine-grained form of continuous deployment a micro-deployment for lack of a better term. With micro-deployments, the microservice versions are bumped and deployed independently, with little need for integration testing.
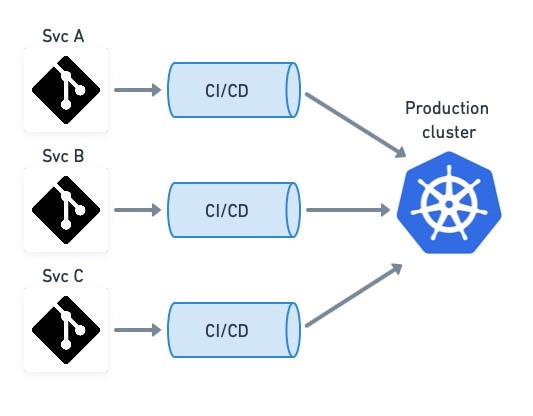
Micro-deployment is a side effect of organizing the code into multirepos. For reference, this is how we currently deploy microservices for Semaphore CI/CD.
Maintaining Multiple Releases
Continuous micro-deployments are ideal for hosted apps like Netflix or Semaphore CI/CD, where users or customers are unaware of (or uninterested in) individual microservice versions running behind the scenes.
Things, however, are very different for someone running the same application on-premise. Continuous deployments don’t work in this scenario. We’re back to release schedules, only in this case, a release consists of a bundle of microservices pinned at specific versions.
Of course, a private Airbnb doesn’t make sense, but a private CI/CD platform does. For instance, you can run a fully-functional version of Semaphore CI/CD behind your firewall with Semaphore On-Premise.

Micro-deployments to the hosted version of the application combined with releases for the on-premise instances of the product.
The steps needed to release an application organized into multirepos usually go like this:
1. In each repo, tag the versions of microservices that will go into the release.
2. For each microservice, build a Docker image and map the microservice version to the image tag.
3. Test the release candidate in a separate test environment. This usually involves a mix of integration testing, acceptance testing, and perhaps some manual testing.
4. Go over every repository and compile a list of changes for the release changelog before updating the documentation.
5. Identify hotfixes required for older releases.
6. Publish the release.
Considering that an application can consist of dozens of microservices (and repositories), it’s easy to see how releasing this way could entail a lot of repeated admin overhead.
Managing Releases With Monorepos
As we’ve seen, multirepos are better suited for continuous deployment than for periodical, non-continous releases. So, let’s see what happens on the other end of the spectrum, when we gather all the microservices into a shared repository. This is the monorepo approach, which companies like Google, Airbnb, and Uber have been using for years.
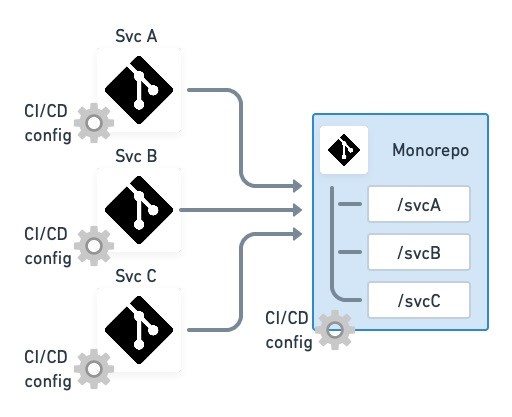
A monorepo contains all the microservices and a unified CI/CD deployment pipeline.
The monorepo strategy makes microservices feel more like a monolith, but in a good way:
Creating a release is as simple as creating branches and using tags.
A single CI/CD process standardizes testing and deployment.
Integration and acceptance testing are a lot easier to implement.
A single Git history is much clearer to understand, simplifying the process of writing a changelog and updating documentation.
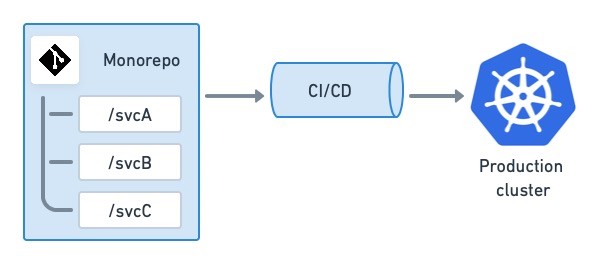
One CI/CD to rule them all
As always, changing the paradigm involves some tradeoffs:
Because all changes are committed in one place, the CI server is under more strain. We can deal with this by using change-based execution or a monorepo-aware tool like Bazel or Pants.
Git has no built-in code protection features. So, if trust is a factor, we should use a feature like Bitbucket or GitHub CODEOWNERS.
Finding errors in the CI build can feel overwhelming when the test suite spans many separate services. Features like test reports can help you identify and analyze problems at a glance.
A monorepo CI/CD configuration can have a lot of repetitive parts. We can use environment variables or parametrized pipelines to reduce boilerplate.
Never Too Far Away from Safety
Up to this point, we’ve only focused on the application’s releasability, but there is another factor that might give monorepos an edge.
Version control not only allows us to collaborate, share knowledge, keep track of the code, and manage changes, it also provides the ability to recover when something breaks. As long as we have access to every change in the project, we can always go back.
Multirepos, however, cannot offer a complete picture. There is no record of the relationships between the microservices, i.e. there is no snapshot of the individual service versions running in production at any given time. As a result, diagnosing integration issues can be time-consuming, and there could be instances when fixing a problem by rolling back microservices is impossible.
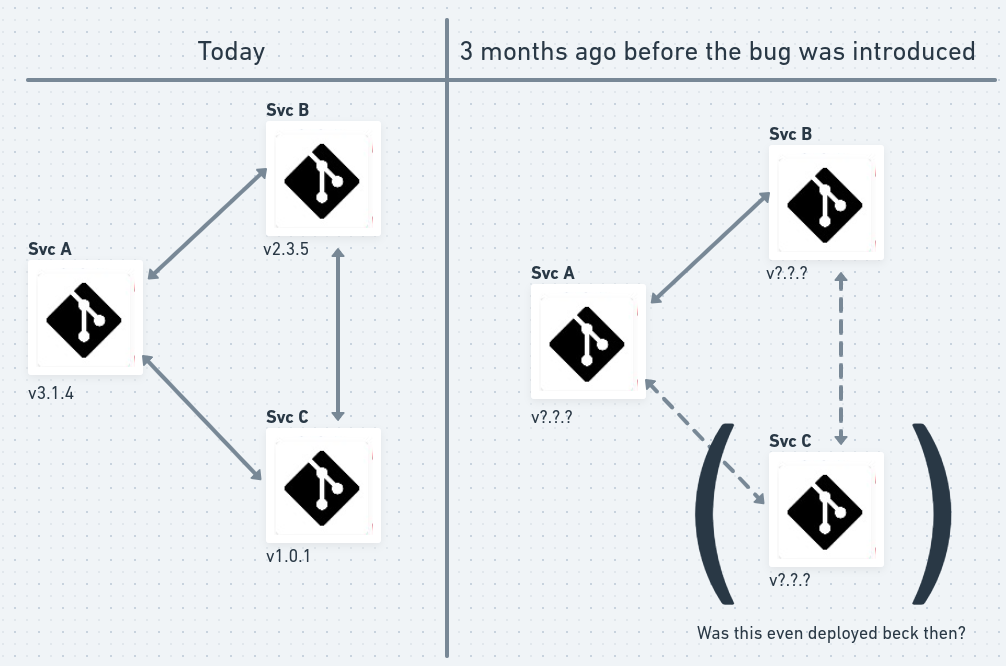
Multirepos make it
challenging to find the root cause of a failure. It’s difficult to find the
“last working microservice configuration.”
Monorepos don’t suffer from this. A monorepo captures the
complete snapshot of the system. We have all the details needed to return to
any point in the project’s history. So, we’ll always be able to find an
appropriate place to retreat to when there’s a problem.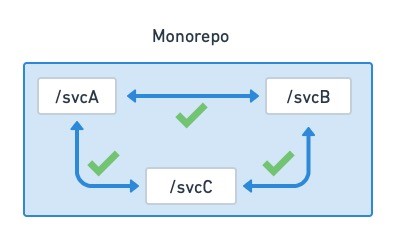
A monorepo has all the microservice relationship details needed to go back to any point in the project’s history.
Final Words
One pipeline and one repo per microservice? Or one shared repo and a global pipeline for everything? There is no single best answer that will fit every scenario. If your microservices are loosely coupled, either a multirepo or a monorepo will work perfectly fine. Multirepos require more work but provide more autonomy. However, if your services are somewhat coupled, it's best to make that relationship explicit by using a monorepo. So, when in doubt, a monorepo can be a safer bet, provided you can live with the tradeoffs.
Continuous micro-deployments have worked well for us at Semaphore, but Semaphore On-Premise is forcing us to adjust. While the final solution is still a matter of some debate, it is almost certain that it will involve migrating the core microservices to a monorepo.
Thanks for reading!
We Provide consulting, implementation, and management services on DevOps, DevSecOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant blogs:
DevOps Security Checklist for Kubernetes
A Checklist for Building a DevOps Organization
Testing Strategies for Microservices
5 Options for Deploying Microservices
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post