Taking AI/ML Ideas to Production

Let's look into how we can make the AI/ML models production ready and how to automate the whole process.
The integration of AI and ML in products has become a trend in recent years. Companies are trying to incorporate these technologies into their products to improve their efficiency and performance. And this year, particularly with the boom of ChatGPT, almost every company is trying to introduce a feature in this domain. One of the main benefits of AI and ML is their ability to learn and adapt. They can analyze data and use it to improve their performance over time. This means that products that incorporate these technologies can become smarter and more efficient over time.
Let's understand now how companies are taking their ideas to production. Usually, they start with hiring a few data scientists who will figure out what models to create to solve the problem, fine-tune them, and handover to MLOps or DevOps engineers to deploy. Your DevOps engineers may or may not know how to efficiently take these models to production. That's where you need specialized skills such as Machine learning engineers and MLOps who understand how to manage the whole process of the CI/CD/CT pipeline efficiently.
Maturity of Deployment Strategy
Many engineers will start with packaging the model and APIs in a popular Python framework, like Flask or FastAPI, in a container and deploy on Docker or Kubernetes. This works well for the lab type of environments but is not meant for production use cases.
More mature companies come up with their tooling to orchestrate and deploy the service. I think they are well set, but their system is not aligned with the ecosystem and requires a lot of effort in managing and maintaining the system over time.
Lastly, you are at the rightmost side where you deploy a specialized machine learning platform such as Kubeflow, Ray, ClearML, etc. which provides end-to-end tools to manage the lifecycle of ML service.
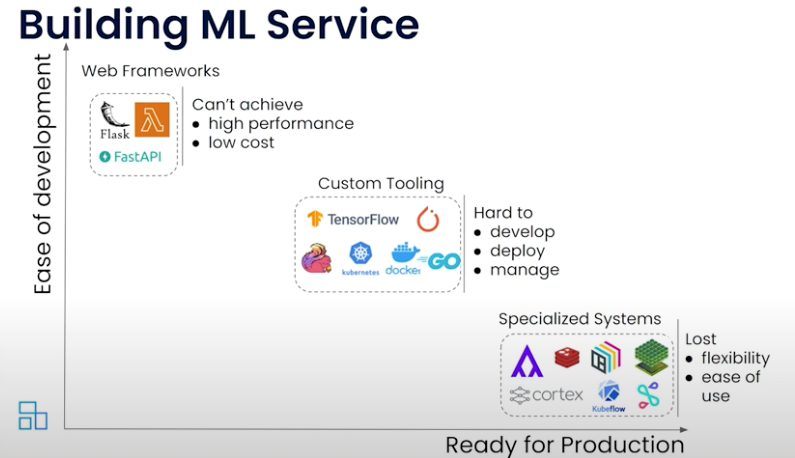
Credits: Model Serving at the Edge Made Easier: Paul Van Eck and Animesh Singh, IBM
Where to Start?
If you are new to MLOps, it is not so easy to understand what exactly you need in your stack. To simplify this, the MLOps community has shared a template that can help you to do some self-assessment and navigate the large AI/ML platform ecosystem.
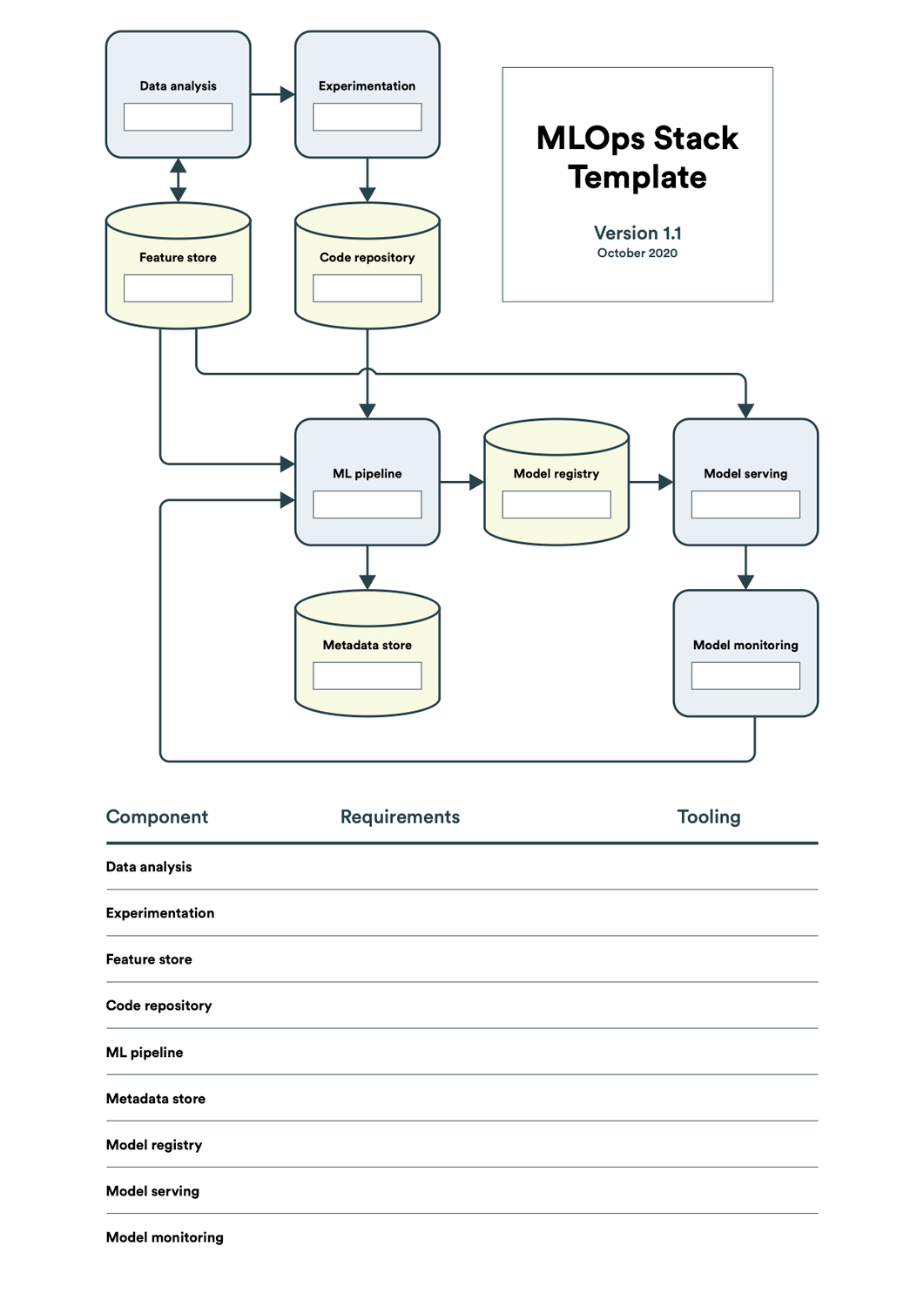
Not all the components are required in the stack, but you can put your requirements for each component and identify the tool that works for you. Essentially, you need a way to bring data to the platform with version control, run and record experimentations, an ML pipeline to automatically run the code that your data scientist is framed in the notebook, and a model registry where you will store the models and their lineage, followed by model serving and monitoring the performance of the inference.
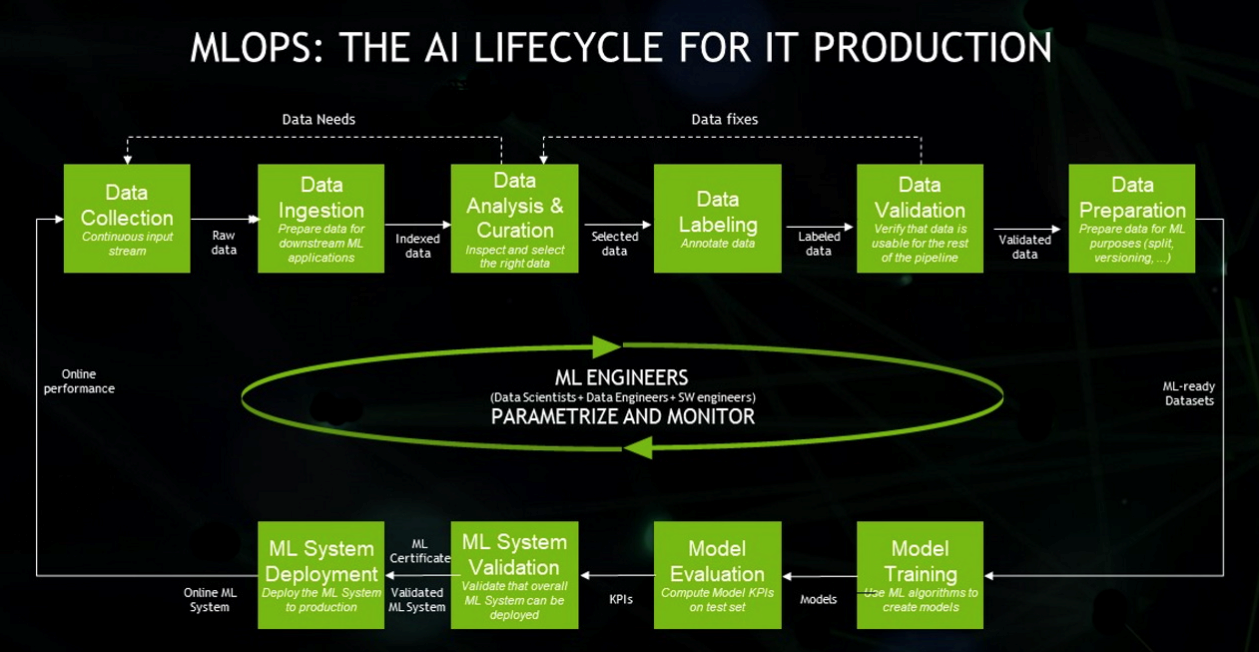
Lifecycle of AI/ML Project
Finding the Right Tool for the Job
As I stated earlier, the ecosystem is thriving, and there are hundreds of tools and frameworks coming up to manage a subset or the full lifecycle.
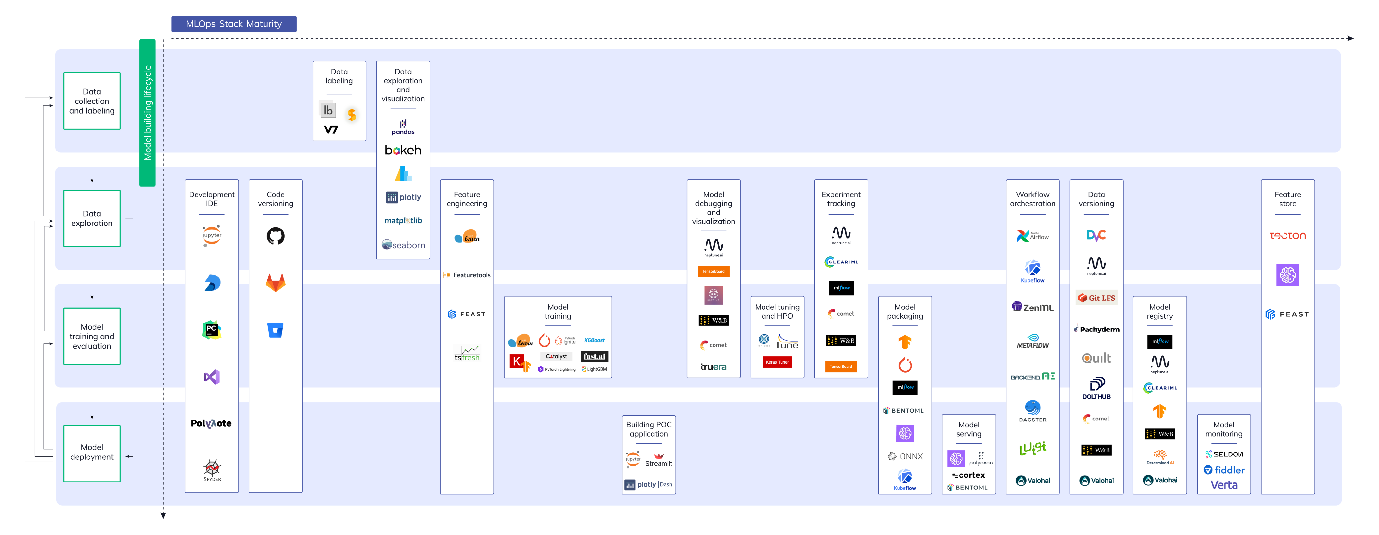
Neptune.ai has compiled the above stack, which I find quite useful for understanding how these offerings are fitting together. Here are some choices that you can explore.
Here are some choices that you can explore.
Cloud Offering
If you are in any major public cloud, you will get access to the services like Vertex AI in Google Cloud, Sagemaker in AWS, and Azure ML in Microsoft Azure. They have done a pretty good job making useful end-to-end lifecycle management. Some of them are more mature than others, obviously, and some of them are not very cost-effective. For example, I don't find their model serving options not very efficient. They don't allow you to use fractional GPUs or run a copy of a full GPU machine during deployment rollout.
Build Your Stack on Kubernetes
If you are brave and want to take some open-source framework like Kubeflow or Ray, you can create your stack. These frameworks are mostly complete when combined with MLFlow.
Commercial Products
Lastly, there are players like truefoundry, weights and biases, ClearML, etc., that provide the full solution with minimal operational overhead. ClearML is also available as an open-source self-hosted version, but then you back to point 2, building your stack.
There are many more tools and products available, but I don't want to focus on them; instead, I want to give a rough sketch of the stack. Whatever you select, the de facto industry standard to host these MLOps stacks is Kubernetes; sometimes cloud provides management for you to simplify the operations and sometimes leaves it to you to run on your clusters.
Challenges
- Most often, we overlook data privacy and security and only realize this when we are hacked or need to get some compliance.
- Lack of skilled resources who understand the ecosystem well.
- Sparsely spread tooling, which is not production ready. For example, I have found many popular tools in the MLOps stack lacking RBAC and authentication.
- A wrong or lack of understanding of the right stack leads to inefficient processes.
- Inefficient use of computing such as GPU can blow your cost. We often overlook cost initially and realize only later when we are hit by a bill shock.
- An inefficient underlying platform could be your Kubernetes cluster which is not efficiently handling computing, has unreliable cluster design, etc.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, DataOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post