Third Generation Data Platforms: A First Look at Microsoft Fabric

Learn about Microsoft Fabric (now in Public Preview): a unified SaaS platform representing the next evolution of data platforms in the Azure cloud.
Evolution
Towards the end of 2019, Azure SQL Data Warehouse was integrated as 'Dedicated SQL pools' into Synapse Analytics. Synapse brought in additional Serverless and Big Data Analytics capabilities.
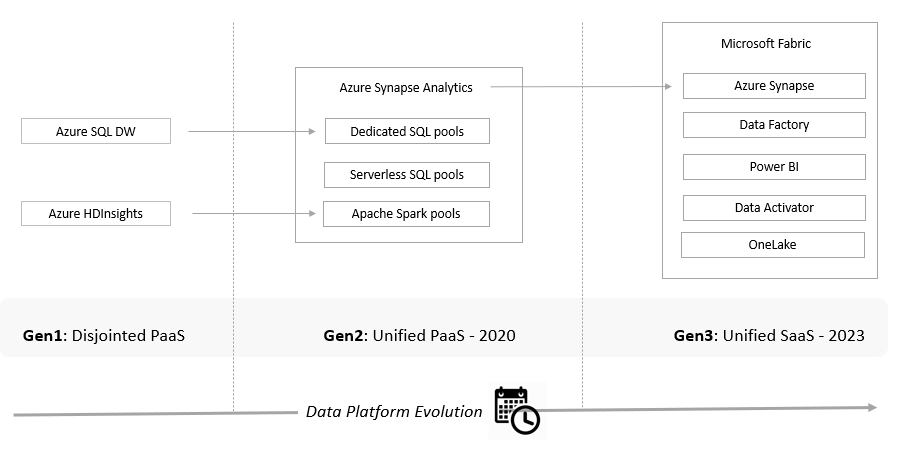
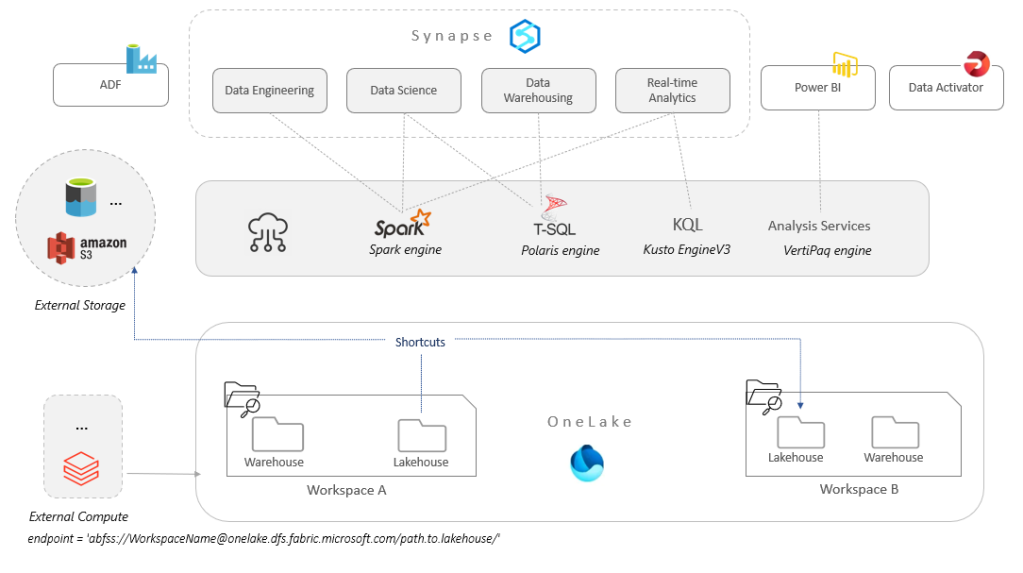
Microsoft Fabric, now in Public Preview, represents the next evolution of data platforms in the Azure cloud, unifying a bunch of PaaS services into a single SaaS platform. Fabric is presented as an end-to-end, unified analytics platform serving engineers, data scientists, business analysts, and business users alike. The components of this new platform are of two main types:
- Pre-existing, well-known services, such as Synapse Analytics, Data Factory, and Power BI, have nevertheless been upgraded
- New services, like Data Activator and OneLake
There isn't much to comment on Data Activator, since that service is not yet available for preview. Its purpose would be to monitor data sources and potentially trigger actions.
Then there is OneLake, which is a core concept in Fabric, presented as the "OneDrive for data."
OneLake For All
Built on top of Azure Data Lake Storage (ADLS) Gen2, OneLake can apparently span regions, so it is a logical data lake, a front-end to multiple storage accounts, all managed under the hood. Every Azure AD tenant has exactly one OneLake.
Some notable OneLake features to mention are as follows:
1. Any number of workspaces (basically, the top folders in the lake that appear as containers) can be created in OneLake, each within different regions, access policies, and separate billing. Each workspace may contain a number of lakehouses, warehouses, files, etc., and represents a single domain or project area where teams can collaborate on data. Security in the workspace is managed centrally through roles.
2. OneLake supports instant mounting of existing storage with the Shortcut feature. Shortcuts are OneLake objects that enable easy sharing of data between users and applications, without having to move and duplicate information (zero-copy). A shortcut is similar to a symbolic link, basically a pointer to data stored in other locations such as other warehouses or lakehouses, external data lakes, or even another cloud provider's storage services such as Amazon S3.
3. Files representing tables in OneLake are stored in the open, ACID-compliant Delta format, enabling better interoperability with other systems. To be a tad more specific, there are a couple of typical subfolders under the lakehouse top folder:
o The /Files subfolder, which contains raw files in different formats, e.g., CSV, JSON, etc.
o The /Tables subfolder, which is where processed files are stored in Delta format
Note that Delta is basically the language-agnostic, columnar-storage Parquet format with a transaction log called the Delta log.
Lakehouse vs. Warehouse
When we create a lakehouse, a number of items are also automatically created:
- A warehouse
- An SQL endpoint for that lakehouse, which is using the same engine as the warehouse to expose Delta tables to T-SQL queries
- A default Power BI dataset for that SQL Endpoint.
In the warehouse, user tables are stored in Delta format. Any engine that can read Delta Lake tables will be able to query those tables.
Deciding on whether to use a warehouse vs. a lakehouse ultimately comes down to the type of work being done and who is doing it. Lakehouses and warehouses can also be further combined, e.g., into another warehouse, as shown below.
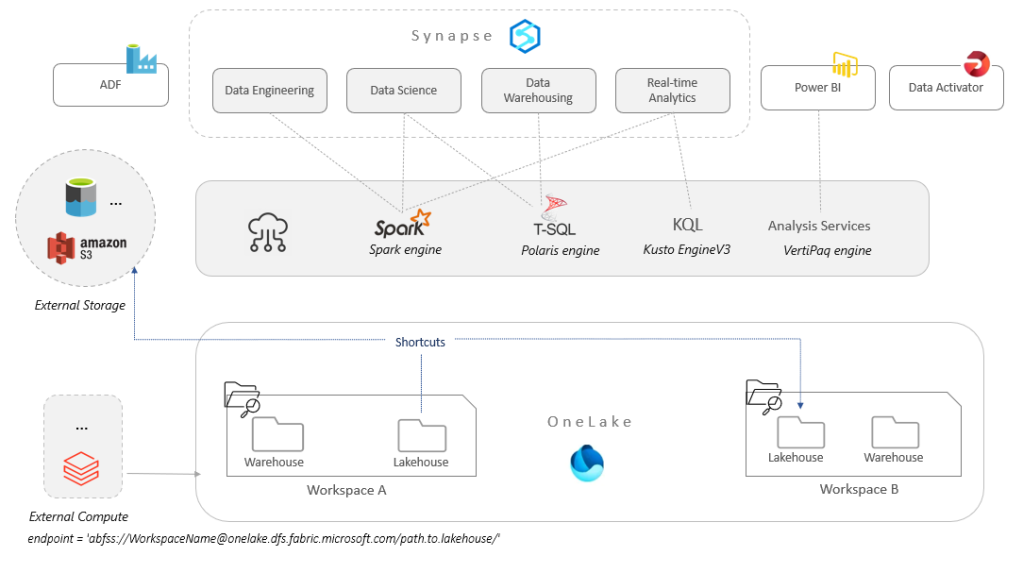
A common scenario would be that of a medallion architecture implementation, where the files are processed at increasing levels of quality, from raw (bronze) to consolidated (silver) and then refined (gold) layers. In this case, the generated gold Delta tables destined for consumption can be accessed by the warehouse using T-SQL through the SQL endpoint, even when they are located in external data lakes (thanks to shortcuts).
Note that, while T-SQL queries can be run on lakehouses, tables created using Spark cannot be updated using T-SQL. As with the "old" Synapse Serverless, DML functionality (insert/update/delete) is not supported. The workaround would be for those tables to be re-created in the warehouse using CTAS (CREATE TABLE AS SELECT).
Similarly, warehouse tables created using T-SQL can be read by Spark, but not modified. Basically, Fabric lakehouses and warehouses can only read from each other. For writes, they need to create equivalent tables in their respective environments.
This limitation seems a bit odd. Since the data is ultimately stored in Delta format, are Fabric warehouses that different from Fabric lakehouses? Other competing services also converging into unified Analytics platforms, such as Databricks or Snowflake, do not appear to have such issues.
Final Thoughts
As each workspace is an independent domain inside one logical storage, Fabric enforces compliance policies and security settings centrally, while at the same time enabling distributed ownership of data in organizations.
Besides vendor lock-in, the other main issue with SaaS solutions, in general, is that they come with an opinionated view on how things should work, leading to limited customization options, loss of control, and flexibility. SaaS products provide specific integration points, but they generally can't offer the same level of flexibility and extensibility as PaaS services. That may work well for some, but not so much for others.
That said, it would be unfair to characterize Fabric as a simple rebranding of existing services. There has been substantial work done on the underlying engines (e.g., the Synapse Polaris engine) to make them more performant, and on the new Delta-native nature of warehousing. For instance, Fabric engines can now produce v-ordered Delta files. V-ordering is a write optimization that enables fast reads.
On the marketing side though, the decision to use the term 'Fabric' is not exactly optimal, as it collides with other, very different services (Azure Service Fabric) and might cause a bit of confusion.
As a side note, MS Fabric is soon (?) to be augmented with the Azure OpenAI Service in the form of Copilot. According to MS, with Fabric powered by AI, users will be able to use conversational language to “create dataflows and data pipelines, generate code and entire functions, build machine learning models, or visualize results." Curious to see how well that'll work.
This has been mostly an overview of OneLake, as it lies at the core of the Fabric platform. At the time of this writing, Fabric is still in Public Preview, which means that the information shared in this article may turn out to be inaccurate later on.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, DataOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post