Why Is Branching in GitOps a Bad Idea?

Why Is Branching in GitOps a Bad Idea?
In this post, I will share why the branch-to-environment approach is counter-intuitive and unacceptable. I'll also discuss what to do instead of branches.
GitOps is a pattern for the continuous deployment of cloud-native apps. The infrastructure is operated with the help of continuous deployment tools and a Git repository, which contains information concerning the necessary infrastructure and automated processes. You only need to update your Git repository to update a specific app or deploy a new cloud app.
For instance, the GitOps environment makes it possible to deploy apps more often, safely, and faster without switching between diverse options. Developers possess a unique opportunity to release updates up to several times a day and implement them, deploying instantly and monitoring the results in real-time. Moreover, they can collect feedback, and, if necessary, make changes or roll back to a previous version of the product. So, GitOps is the best thing you can do with configuration as code. But there are nuances too.
What's Wrong with Git Branches?
Weave GitOps supports the scenario of adding different branches, and at first or for want of habit, this may seem like a convenient solution. But some issues can stay hidden for some time. They become noticeable only when you must proceed to the merge process. This happens because you must move the repository configurations to a separate file, add an entry to gitignore, etc. for proper migration.
It is not beneficial to apply multiple Git branches in a simulation in various environments. We always try to convey this idea to development teams. Nevertheless, there are exceptions.
Usually, we have at least 3 steps of env to pass before production env (including the last one):
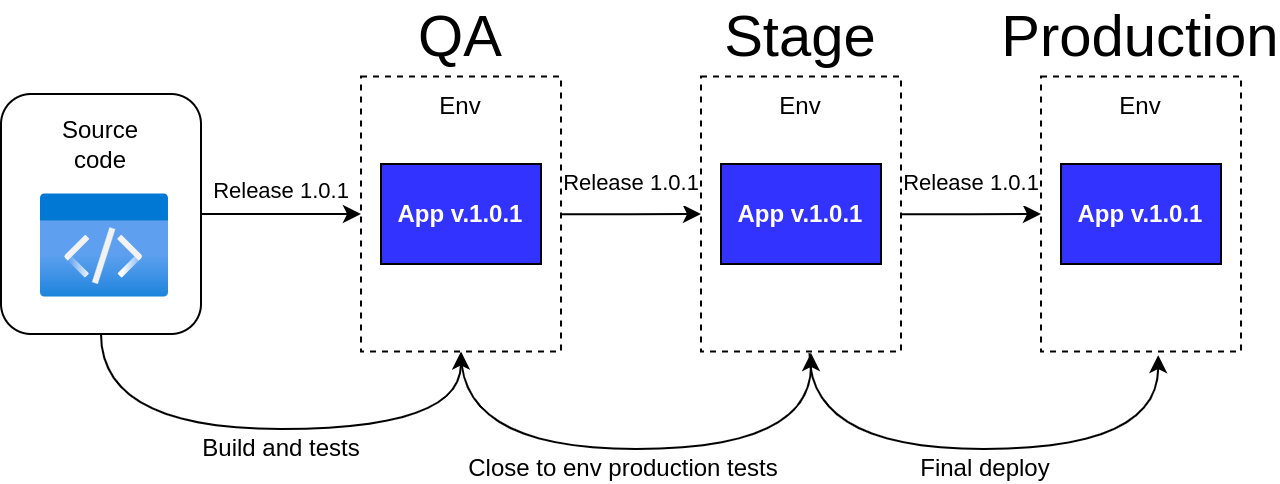
If "Production," "QA," and the like branches are present in a Git repository, you may assume it is a pitfall. Let's discuss why. We have reason to state that more modern and simpler approaches exist, which are logical and technically correct to use in such a case.
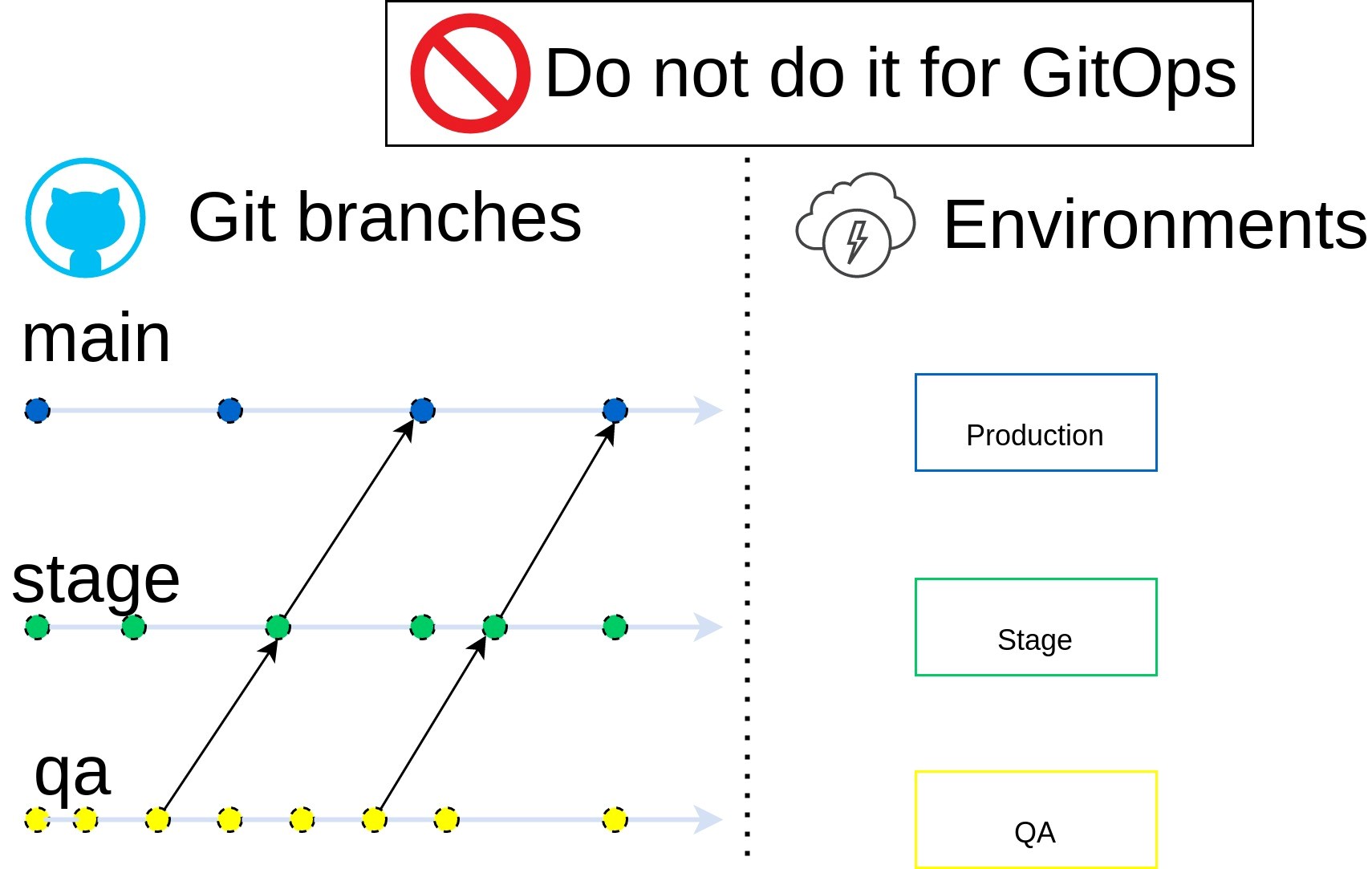
But first, let's remember why the engineering community adopted GitOps in the first place.
Advantages of GitOps
And why they are definitely not compatible in separate branches:
Automation
Synchronization from Git, just like the execution of edits in Kubernetes, occurs automatically. Why complicate and slow down the process with a huge amount of manual work when it is possible to do it all automatically.
Convergence of System
That means that it strives for a synchronized state even during periods when something changes in Kubernetes or definite improvements are made to Git, but they have not yet been delivered to the K8S. If the system tends to get in sync, and modifications of branches require a huge amount of manual and repetitive work, the principles of Kubernetes are violated, and one more major benefit is lost.
Idempotency
Independence of every subsequent synchronization wave from previous ones. With characteristic branches not committed to Git, the system begins to collapse like a house of cards because it is unrealistic to guarantee that changes at a certain stage, not agreed with the development team for some reason, will not affect the final state of the product (we will discuss this issue in more detail later).
Kubernetes is still criticized for not simplifying the product after 8 years, and there are questions regarding observability and security. But if the environment itself is quite complex, how much sense does it make to complicate the process of developing and rolling out updates and releases even more?
Top 4 Reasons to Stop Using Git Branches
So, we found out that you should avoid employing Git branches in a case where your application should use a cloud environment. But so far, we have only stated this, and now, we will explain what real problems such an approach leads to:
1. When there are several branches, each of which undergoes changes at diverse stages, serious conflicts can arise during merging.
2. If a few products are in operation, more tasks will arise soon. At some point, you will be unable to keep up with them.
3. The current Kubernetes ecosystem does not support a Git branch fork model for every environment.
4. <!--[endif]-->Including very specific blocks of code causes configuration drift and some serious issues in the edge environment.
As an exception, legacy apps that are still supported should be able to include branches. The use of branches in a Git repository can still be logically justified only in such cases. Exceptions end here. In all other cases, the approach using branches turns out to be irrational.
When Do We Still See Branches in a Git Repository?
During checkouts, it turns out that branches appear "the old-fashioned way" and "out of habit" because developers have always done this, and they consider this order of things natural. The reason is the Git-Flow model, which implies the use of branches for various environments. But Git-Flow has some features that make such a scenario quite acceptable there, unlike GitOps, where, as we have already found out, using branches is tantamount to creating problems dealing with which will be inevitable.
Why Are Branches Allowed in Git-Flow?
Considering the Git-Flow model is designed to work with app source code rather than configuration, it permits branches. Moreover, it is applicable when multiple production versions of the same environment are supported. Or, this option is suitable for maintaining multiple production versions of the same environment at once.
Returning to GitOps, we remember that the app code and configuration demand distinct repositories. Including branches in the environment repository here by adding them to source code repositories can cause unforeseen difficulties.
It turns out that while remaining true to GitOps, developers agree on the necessity to deploy every new project from scratch without resorting to branching the source code of another application. Git configuration repositories should remain flat, without branches for every environment.
You Can't Build a Quality Git Merge App
The possibility to simplify the work of developers and imagine that a simple merging with Git will be enough sounds great. One could even support this theory by saying that when moving from QA to an intermediate product, you just need to merge the source and intermediate branches and then again merge the intermediate branch with the production branch. Certain insignificant scenarios may indeed be duplicated in the method described above. However, when deploying cloud applications in GitOps, this model does not work.
A product release by merging with Git will suffer from a merge, incorrect order of modifications, or a whole bunch of inappropriate shifts, which will ultimately affect the quality of the product that goes directly to the end-user.
Example
How can "branches" cause any problems? Let's assume you have some kind of intermediate version of the product. Meanwhile, someone has already managed to change the intermediate version, reducing the number of replicas in it due to limited resources. When merging the QA branch with the staging branch, you are still sure that everything should work properly but have no idea of where to look for the basis of issues later.
Yes, you could check if the number of replicas in folders matches, but you will hardly do such a preliminary check with multiple scripts and numerous manifests before merging, which are mostly templates. In reality, it is rather difficult to determine what modifications must be made and what should be left as is.

Much manual work is required to determine where parts are needed, what shifts require promotion, and where the promotion order does not match the commit order. You must plan everything correctly. Unconventional methods like git cherry-pick or similar might be required. As a result, it turns out that the task has gone too far from a "simple" Git merge, to something requiring too much manual labour, care, focus, and additional techniques and tools.
More difficult cases can be encountered, such as when cherry-pick might not help to cope with the task. If this happens, it becomes quite obvious that merge is impossible because of dependencies between commits, and configuration complexities and conflicts are unavoidable.
You can see that release 1.0.1 must be migrated to production but there are many modifications in the patch commit. Iterations made on the incoming configs of another commit directly affect some of them. Such transformations cannot be applied to the production environment because they apply to intermediate files only. So, even using extraneous methods or tools, you cannot transfer the release from the preparation stage to the production stage.
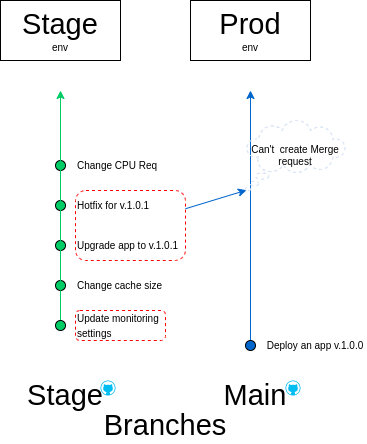
This example is simplified. In organizations and real-life examples, you might see that applications run in numerous clusters, which, in turn, consist of many manifests. The manual selection of commits is a task that can take years to complete in this case.
Theoretically, no negative outcomes should be encountered when you merge Git with a configuration drift. After you modify the staging environment and merge the branch into the production version, the new environment is updated automatically. Unfortunately, things may go wrong because several specialists work on the project. The upstream environment can be modified without the new settings in the downstream version, which flow only upwards.
Pay attention to the scenario above. All deployments to it fail due to undocumented transformations in the production environment. New manifests that subsequent updates cannot detect can also lead to crashes.
It is hardly possible to improve the issue manually if there are not many branches. You can manually merge the desired commits in multiple environments. But, as we have already found out, the number of commits directly depends on the number of tasks a project has, their number and revisions become uncontrollable eventually. Hence, pushing releases by merging with Git adds new problems. Other members can add modifications, and they will not move sequentially. As a result, configuration drift is exacerbated rather than eliminated.
Is It Possible to Manage Git Branches in Multiple Environments?
Unfortunately, it is unrealistic. Let's assume you have only three qa->staging->production branches. Nevertheless, it will be necessary to manage them in multiple environments. However, it turns out that the number of branches and parameters that must be configured is bigger. You can add some additional ones to the main list, such as geolocation, production, etc.
The more parameters and branches, the higher the likelihood of an incorrect merge. Also, the project is not insured against accidental shifts. Configuration drifts occur. But the main conclusion is that a separate branch for every environment leads to troubles that developers might not have encountered if they had chosen another approach to work on the application.
How Does the "Branch to Environment" Script Conflict With Helm/Kustomize?
Tools, such as Kustomize or Helms, helps template for apps. Helm creates a separate chart and adds it to the values.yaml file. These types of files are created separately for every environment.
In the case of the helm tool, you should first create a basic chart (or reuse already existing), then create different values for different environments. So, these values will be set values in the templates of your helm chart.
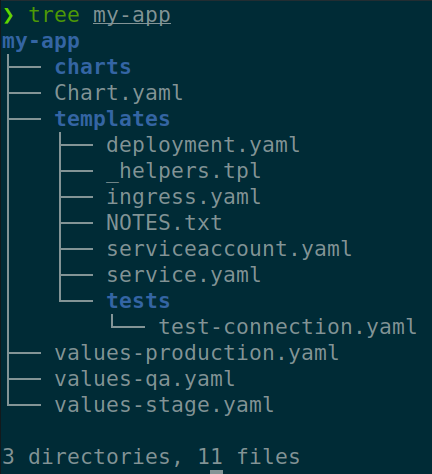
Kustomize helps create a basic configuration, and every environment turns into an overlay with an independent folder.
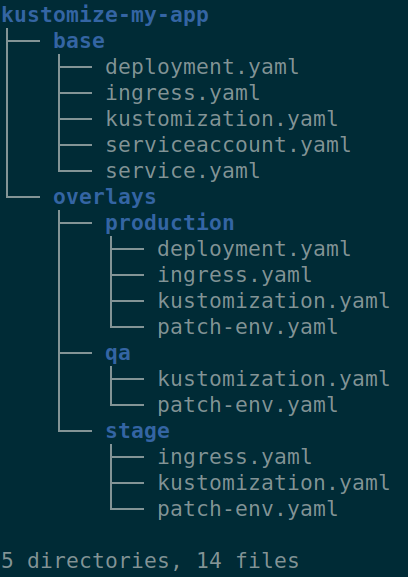
It turns out that both tools involve modelling the environment, applying different values of files or folders. However, neither Kustomize nor Helm are related to Git branches, and they have nothing to do with pull requests because they only use simple files. By adding separate Git branches to them, developers can complicate their work with their own hands and even go against their own toolkit.
How to Properly Promote Cloud Product Releases in GitOps?
Clearly, modelling in Kubernetes and porting project releases from one environment to another come with some challenges. However, as you can see from examples, you can’t solve these issues using Git branches. Working with branches and later merging them into new releases is impossible because some issues are inevitable, namely:
- Technical difficulties
- Configuration conflicts
- Loss of control over the project
Together, these factors tell us that branches are an obsolete pattern. If we strive to create working, efficient, and modern software products, they will have to be abandoned.
What to Do Instead of Branches?
If we do not agree with the current state of affairs, we have to find an adequate replacement, which is rather logical. Such an alternative exists. This topic is no less voluminous and requires a separate discussion. In short, the "environment per folder" strategy is becoming a replacement for branches.
The most valuable features of the new method:
No need to submit releases manually.
It is not necessary to control every folder.
The numbers of commits in different folders do not require comparison.
No worries that changes to the original version can be made without prior updates in the intermediate version, etc.
That is, all the potential problems described above disappear. You can stay with the idea that a separate branch for every environment is a good decision, or you can adopt a new, more convenient, and cost-effective way of working.
Does this mean moving "environment per folder" should use one branch for the YAML repository and copy the configuration from one environment folder to another to promote product versions across various environments? Definitely. The method allows you to benefit the most from every environment and not keep track of the order of commits and their number anymore since this factor becomes completely unimportant.
Keep in mind the major purpose of using GitOps – the possibility to quickly deploy an application to the cloud and make as many changes to the product as needed. This process should be easy for developers and other members of the team working on the creation or deployment of the product, and it should not cause any problems on the customer side.
Therefore, the branch-to-environment approach is counter-intuitive and unacceptable, although it is still used in an old-fashioned way by some teams managing to create working systems, this is in spite of, rather than thanks to branches. Besides, "branches" require significant attention, and they are associated with huge labor costs.
But it doesn't make sense to convince you to use the "environment per folder" method. If you encounter the issues described above at least once, you will understand that the use of multiple branches has ceased to be an anti-trend. And then, the new development strategy will become quite natural and familiar to you.
ZippyOPS Provide consulting, implementation, and management services on DevOps, DevSecOps, Cloud, Automated Ops, Microservices, Infrastructure, DataOPS, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist:
https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
Aws attach volume to running ec2 instance
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post