Why Kubernetes Observability Is Essential for Your Organization

Why do you need Kubernetes observability? Let's understand the three pillars of observability and dive into some challenges in implementing observability.
The Kubernetes service simplifies load balancing and container
management of containerized applications. Simply put, it makes it easier for
enterprise applications to have greater scalability, flexibility, and
portability. After Linux, Kubernetes is one of the fastest-growing projects in
the history of open-source software. According to a study by CNFC, the number of Kubernetes engineers grew by 67% to 3.9
million.
It is a go-to solution for cloud orchestration in distributed
environments. But, cloud architecture has become complicated, and organizations
find it challenging to fix the bugs. When developers need to address the root
cause, they encounter a lack of observability due to non-tracking of the state
of Kubernetes, serverless functions, and other aspects of cloud architecture.
This lack of visibility into what’s going on led to the need for Kubernetes
Observability.
What’s Kubernetes Observability?
Observability is the potential to measure the current state of a
system based on logs, metrics, and traces.
In the modern environment, the cloud infrastructure, container,
and microservices, etc. are all potential data sources generating loads of data
every day. The main objective of observability is to facilitate a holistic
assessment of all this data coming from disparate systems.
Kubernetes observability helps address issues by bringing
everything into context and takes you to the root of the issue. This leads to a
shorter time for resolution, prevention of issues blowing up, and huge cost
savings in the form of averted crisis.
Three Pillars of Observability
The term observability is best described as the ability to
observe systems via different external outputs in order to detect any irregularities
and fix them.
Talking about the external outputs, these are generated by
systems. They fall under three main pillars:
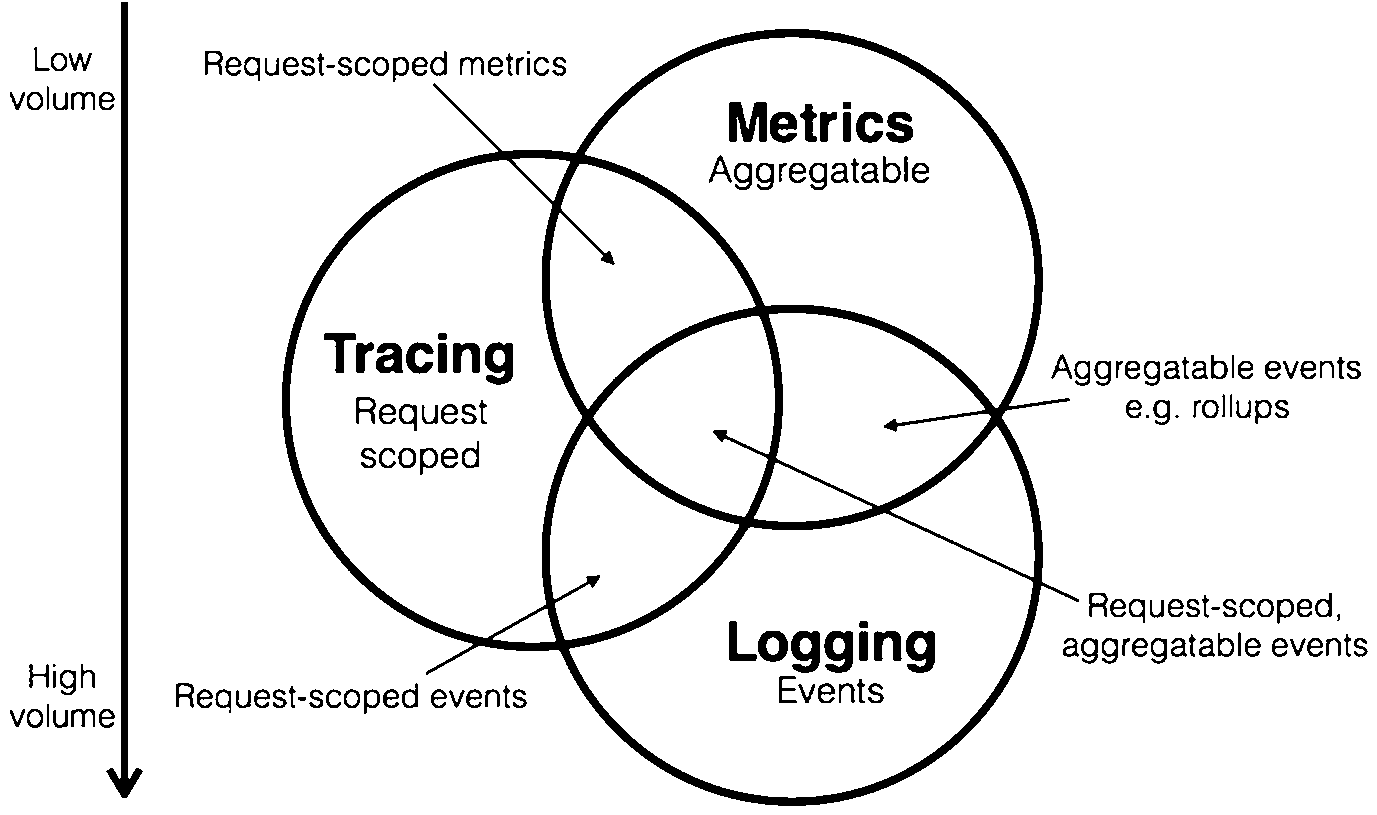
#1. Logs: They are files that store events, warnings, and
errors, which generally occur in the software environment. Logs contain
contextual information. For example, the particular time of an event. The log
messages represent data in three forms i.e., plain text, structured, and binary
format. However, log messages require ample storage space. Therefore, make sure
you have enough storage space before generating them.
#2. Metrics: They are a numerical representation of data. It can
be used to determine the service or component behavior over a specific period
of time. This pillar embraces a set of attributes, such as name, value, and
timestamp, which transfer information about SLAs, SLOs, and SLIs.
Metrics are real-time savers. This is because one can easily
correlate them across infrastructure components in order to get a holistic view
of system health and performance. It also enables longer data retention.
If you want to know about what is happening in your system and
notice a sudden spike in traffic, then metrics provide deeper insights and
visibility. It helps you understand the reason for the spike, such as malicious
behavior or incorrect service configuration.
#3. Tracing: A trace represents a series of causally related
distributed events, which encode end-to-end request flow via a distributed
system. In actuality, traces are a representation of logs, and a single trace
looks like an event log.
Challenges in Implementing Observability for Kubernetes
Dealing With Data Silos
Conventional monitoring tools are built to collect metrics at
the application and infrastructure levels. Kubernetes is dynamic, ephemeral,
and distributed in nature. The collection style of these tools creates data
silos. When DevOps include more metrics for observation, data silos can lead to
uneven cross-references and data misinterpretation, leading to slower
communication and error-prone analysis.
Managing Large Volumes of Data
Deployments in Kubernetes depend on different components like
pods, containers, and microservices. Such are a part of the ephemeral and
distributed infrastructure. And it results in the entire system generating a
great volume of data at each layer. It also keeps increasing with the
multiplying scale of services. It becomes hard to track patterns and follows
debugging, making observability and troubleshooting all the more complex.
Waiting Time Troubleshooting
Several teams (application, infrastructure, and digital
experience) try to identify the root cause of problems and waste valuable time.
Also, they try to make sense of telemetry and come up with solutions.
Keeping Up With the Dynamic Nature of Kubernetes
Undeniably, Kubernetes clusters are complicated. Due to its
continuous evolution, the container instances will increase and decrease when
the demand fluctuates. Thus, the logs, traces, and metrics accumulated at one
time may not resemble the same ones. In the same way, the configuration for the
log and metric stream will change periodically.
One of the best practices to maintain observability in real-time
is letting your teams get insights into the system even though the existing
state of clusters is different.
Why Is Kubernetes Observability Essential for Your Business?
In an organization, when the team of developers struggles to
track the state of Kubernetes and serverless functions, they address the root
cause of their problems, i.e., lack of observability.
When it comes to an understanding the idea behind the term
“observability,” then it is not a synonym of “logging” or “metrics” or not just
a feature. However, it is the idea of how long the team of developers in an
organization takes time to understand the problem. Plus, how long does it take
to recognize the issue, identify the root cause, and come up with a
solution?
An excellent observability strategy can be best described when
developers look at the dashboard and immediately understand the cause of the
problem. On the contrary, if your team of developers needs to understand the
issue for long hours and check manually in order to fix the problem, the “lack
of observability” is what your organization needs to take action
immediately.
Below are four standards that indicate that your business is
using observability in the right manner to track, visualize, and troubleshoot
the entire Kubernetes environment:
#1. Understand In-Cluster Communication
The most common challenge is understanding communication between
the nodes and pods within a cluster. It can be achieved using standards such as
OpenTelemetry and open-source tools (Prometheus, StatsD, or Zipkin). Apart from
these tools, tracking in-cluster communication gives insight into metrics:
error rates, transaction times, and throughput.
#2. Tracing Requests Around the Tech Stack
Distributed tracing is a method of tracking and observing
requests as they propagate through distributed cloud environments. But, even
though the best system could not cover every step of a request’s path. The
distributed tracing calculates timing information from every part of a tech
stack. It provides an excellent tool while overcoming these monitoring gaps and
chasing intermittent bugs throughout the system.
#3. Tracking Overall Health & Dynamic Behavior
Never underestimate the power of infrastructure monitoring.
Whenever unexpected behaviors and performance issues arise, the first step
needed is to evaluate a cluster's overall health. A business with good
Kubernetes observability practices will be able to track API server stat and
scheduler and understand what's happening at any given moment.
#4. Correlating Log Data & Performance Evaluation
Speed is everything regarding observability, in addition to how
long one takes to solve a problem. To overcome such challenges as delaying data
correlation, it’s recommended to use open-source observability tools like OpenTelemetry.
This tool works well to address this problem by connecting logging data to
other monitoring tools. This way, it makes it easier for developers to
correlate the main causes and check what triggers a particular issue.
On the other hand, the other aspect is correlating performance
evaluation. It includes parent organization or user geography. It lets
developers think outside the box and try new solutions to problems.
Wrapping Up
In this article, you’ve gone through some aspects of Kubernetes
observability, which can help organizations in many ways, such as minimizing
disruptions, maintaining velocity, and enhancing business performance.
The ultimate goal is to elevate your business’ performance. But,
it is not all easy without consulting a team of experts who have expertise in
enterprise observability. So, while choosing an expert for your business, do
the necessary due diligence.
You can comment below if you want to share your thoughts on
Kubernetes observability.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
Securing Your Cloud with Zero Trust and Least Privilege
A Comprehensive Guide to Cloud Application Security Audits
How to Build Security for Your SaaS User Communications
17 DevOps Metrics You Should Be Tracking
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post