16 K8s Worst Practices That Are Causing You Pain

The article emphasizes the importance of understanding and implementing best practices to avoid pitfalls and ensure efficient and secure Kubernetes operations
In our years of experience with Kubernetes internally and with hundreds of customers, we’ve seen several mistakes happen over and over again. Don’t beat yourself up about it – we’ve all been there and done that! But there’s no reason to keep making mistakes. Here are the 16 K8s worst practices that will cause you pain down the line.
1. Using In-Tree Storage Drivers
This one’s pretty simple: in-tree disk and file drivers aren’t going to be supported starting with Kubernetes v1.26 anymore.
Solution? Use Container Storage Interface (CSI) – an open standard API that allows you to expose arbitrary storage systems to your containerized workloads.
The idea here is to use CSI to move those plugins out of the tree. As more and more storage plugins are created and can handle production, nothing should stop you from migrating your application storage to use CSI plugins.
2. Lack of Pod Disruption Budgets
Not having any Pod Disruption Budgets (PDBs) set is just a bad idea if you’re looking to keep the lights on (and who isn’t?).
This is what you lose when you don’t set your PDBs right:
Pod Disruption Budgets are here to protect your application from evicting all/significant n number of pods in a Deployment or even causing data loss in StatefulSet.
When using the Node Autoscaler, you can be sure that it respects PDB rules and downscales your nodes safely, moving only the allowed number of pods.
3. Unrealistic Pod Disruption Budgets That Prevent Any Pod Movement
PDBs push back Kubernetes operations like drain node to ensure your application’s availability. But if your Pod Disruption Budget doesn’t allow any disruptions – not even a single replica – prepare for operational pain. This blocks node lifecycle activities like patching or bin-packing low-utilization nodes to remove excess capacity.
When specifying PDBs, think about the minimum number of pod replicas your application needs. Avoid adding PDBs to single-replica pods (like metrics-server); restarting them might cause operational pain as well.
4. Isolating Workloads Without Strong Requirements for It
Isolating workloads is expensive; it’s a lose-lose-lose strategy to run your workloads with lower performance and reduced availability. On top of that, it costs extra. Your workload runs on fewer nodes with less momentary bursting capacity, and bursting happens at the same moments (CPU, throughput).
Fewer nodes means every node taken down can bring significant capacity down as well, so it’s a risk to application availability. Also, every resource pocket creates cost inefficiencies and limits cost reduction options.
You’re probably thinking: “But we have REQUIREMENTS, and they can’t be challenged.”
You won’t believe how often people come up with made-up assumptions. It’s our SOC2 compliance requirements or data regulation requirements… Whoever has been trying to interpret compliance requirements might not have been paying enough attention.
Try reading the spec; you’d be surprised how few restrictions are in the actual compliance requirements.
You can mitigate risk with softer isolation in Kubernetes by using namespaces, setting requests and limits, and configuring network policies. But if you start creating separate node groups for various workloads without a good reason, you’ll end up driving costs up and hating the silos every day.
Separating production and non-production Kubernetes clusters is actually a good practice and makes compliance audits much easier to pass.
5. Mixing Competing Placement Constructs (NodeAffinity and NodeSelectors)
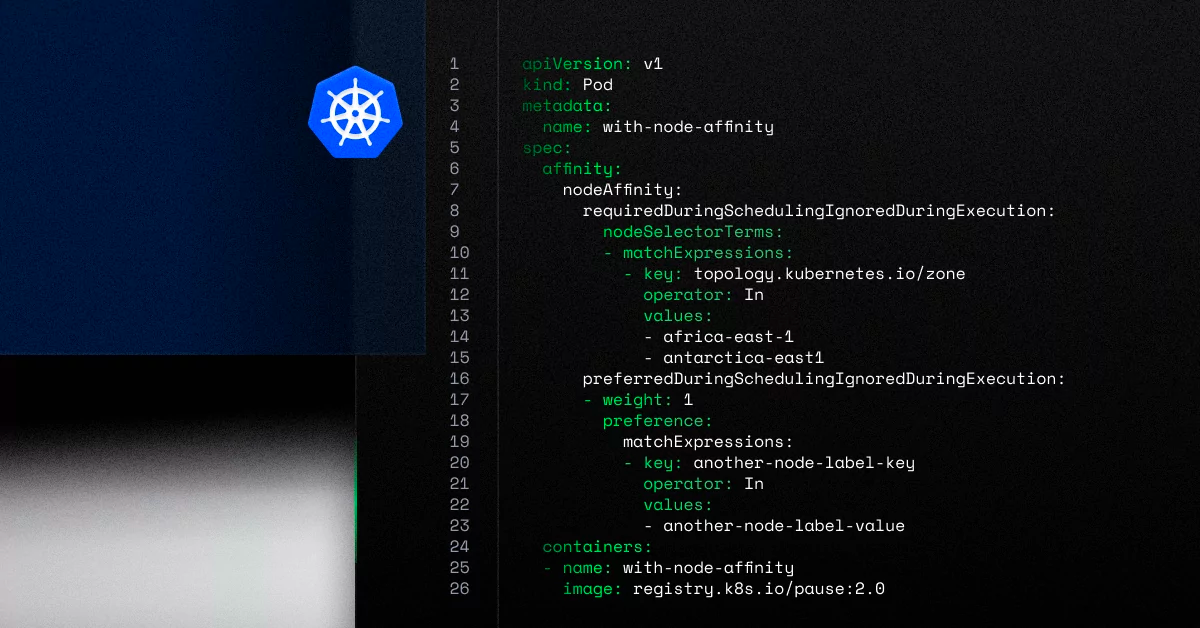
Node selectors were part of K8s for a long time. They’re simple to read but a bit limited.
Node affinity came later. It’s a bit harder to read but more flexible – and hence, more powerful.
The two mechanisms achieve the same goal: they attract pods to nodes with labels. Yup, you’ve got two tools for the same job here.
Teams usually make a decision to use one or the other, and for consistency, stick with one. Mixing them opens the door to configuration errors that might cause workloads to fail to find suitable nodes.
Allow a silly analogy here:
It’s like using tabs (like nodeSelectors – simple) vs. spaces (like nodeAffinity – more flexible). One isn’t technically better or worse than the other. It’s just a matter of preference. But once you decide to use one, you can’t mix it with the other – just like you can’t have tabs and spaces in one file.
6. Not Having Observability in Place
In K8s, observability gives you the ability to troubleshoot issues quickly, thanks to data such as telemetry signals, logs, metrics, and traces. If you don’t have complete visibility into your cluster, you’re in trouble.
Not capturing stdout logs is just criminal. You should write your logs to the standard output (stdout) and standard error (stderr) streams. Make sure to collect these logs at a central location so that you don’t waste time chasing terminated pods and disappearing nodes.
7. Using Burstable Instances To Reduce Cloud Costs
AWS offers some 500+ EC2 instances, and on the surface, burstable instances look pretty attractive. They were designed for workloads with low CPU utilization and occasional bursts.
Just check the pricing data of machines in the T family, and you’ll see a lower price tag. But when you run it, you’re not using CPUs exclusively – you share CPU time with other AWS users, like in an Uber Pool, where you end up sharing a car with some strangers.
Burstable instances often end up being more expensive than they seem, deliver poor and inconsistent performance, and have a confusing SKU – lose, lose, lose. A well-managed Kubernetes with horizontal pod scaling and well-sized pods is more cost-effective.
8. Having Excessive Cross-AZ Traffic
Spreading an application across multiple availability zones (AZs) helps to increase availability and performance, achieve compliance, and optimize costs by choosing the most cost-effective compute within the region.
While data transfer within the same AZ doesn’t cost you anything, if you move it in or out across AZs in the same Region, you’ll be charged $0.01/GB in each direction.
Excessive cross-AZ traffic can bump up your cloud bill in ways you don’t expect. So, do your best to optimize cross-communications network traffic for an architecture that meets your requirements without breaking the bank.
Another good way to reduce inter-zone traffic is to use Kubernetes Topology Aware Routing (via Service annotations). This will try to route traffic between pods in the same AZ, delivering not only cost savings but also network latency improvements.
9. Not Setting Requests
When the Kubernetes Scheduler works, it doesn’t really care about the actual resource usage or limits (kubelet does, though).
So, if you fail to set resource requests, you’ll basically allow your applications to be packed into even the tiniest nodes with no limits (well, aside from the 110 pods per node). Your applications will face CPU throttling, and OOM kills.
Some try to compensate with another bad practice: isolating workload to specific Node Groups rather than addressing the root cause. Every resource in Kubernetes needs to have requests set for it. Without them, the Kubernetes Scheduler operates in the dark – and you’ll pay for that during on-call hours.
10. Not Exposing the Application’s Health Status Through Liveness and Readiness Probes
K8s gives you a bunch of health-checking mechanisms to help you check if the containers in your pods are healthy and can serve traffic. Those health checks or probes are carried out by kubelet:
- Liveness probe – checks when to restart a container.
- Readiness probe – checks if a pod should receive traffic.
This removes the need for someone to constantly babysit your infrastructure, as Kubernetes could do these actions automatically.
For example, if the database was temporarily unavailable, your applications should fail the liveness probe and restart, allowing the pod to reinitiate the database connection without anyone’s involvement.
11. Scaling Workload Replicas Manually
This is just a bad idea.
Having a manual number of replicas in the Dev environment is expected, but keeping the number of replicas static in production is wasteful, especially if the number of replicas goes into 2, 3, or even 4 digits.
Some companies scale by schedule, scale down with a scheduled script, or a CronJob. This solution is better than nothing, but it’s quite fragile, static, and not based on feedback from the real world.
Imagine This Scenario
The marketing team carried out a campaign, and you’re hit with three times the expected traffic. You need replicas dropped. This approach requires constant babysitting.
Scheduling is actually a very good solution for Dev and Staging environments if your engineering team is in the same time zone. This means that you can scale dev workloads to zero replicas during nights and weekends, reducing cloud costs further.
The Kube-downscaler project is good at what it does, and individual teams can define their preferred schedule.
Is CPU the Right Metric for Scaling?
A better way would be to scale replicas based on utilization metrics like CPU by using the built-in K8s HorizontalPodAutoscaler CRDs. If pod utilization reaches a threshold, create more replicas – if utilization drops, reduce replicas.
The problem with HPA is that it uses a metric that doesn’t make sense. K8s capacity auto scalers need a minute or two to add capacity and schedule newly created replicas. This quite often causes HPA to overcompensate, creating more replicas than needed.
Next thing you know, the node autoscaler supplies the needed capacity, HPA starts reducing replicas – and your cluster is left with terrible utilization. Bad data inputs lead to bad outputs, meaning scaling by simplistic utilization metrics causes subpar scaling results.
Here’s the Solution
High-maturity teams scale workloads based on business metrics: number of user sessions, jobs unprocessed, etc. The best tool for the job is KEDA, which can scale based on PubSub queues and database queries (there are tons of scalers, or you can write your own).
This leads to the creation of replicas earlier, quicker scaling decisions, and without overcompensation. Users get snappy performance, and you get much lower infrastructure costs.
12. Running a Self-Hosted Kubernetes Control Plane
It’s like driving stick.
Once upon a time, the automatic gearboxes in cars were laggy and used more fuel. This has reversed, and automatic gearboxes outperform average drivers in performance and fuel consumption.
The same is true for Kubernetes offerings. If someone wants to manage the Kubernetes control plane on their own, they either have very niche needs or are trying to build their resume with skills that have become quite irrelevant in the market anyway.
There was a time when if you wanted to run Kubernetes on AWS, you’d either build your self-hosted control plane with kOps or kubeadm, or you had to use native, half-cooked, unusable EKS. Things have changed.
Does Running the Control Plane on Your Own Make Sense?
Kubernetes offerings from major cloud providers are good enough for 95% of needs (I haven’t personally experienced that 5%). GKE / EKS / AKS control planes cost just $72 monthly and provide automatic scaling and support.
If you want to run your own control plane for 5000-pod clusters, your control plane costs will go well into the four digits. Backups, etc replication delays, API increased latencies, name resolution, and load balancing issues… Why would someone force this pain on themselves willingly?
It might not sound like a benefit, but actually, it’s one of the best – cloud providers force control plane upgrades with strict cadence without the ability to opt out.
I have seen kOps clusters running in production with tens of thousands of CPUs on a Kubernetes version that was four years old and no longer supported (14 minor versions behind). Cloud-managed K8s just won’t allow a similar downward spiral.
13. Not Using Namespaces or Keeping Everything in the “Default” Namespace
When running a relatively small cluster, you might survive without a structure in place. But as your cluster scales to dozens of pods and hundreds of containers, you can’t afford this chaos anymore. Not using namespaces or keeping everything in a “default” namespace are both really bad ideas.
Kubernetes namespace and similar are the answer.
By keeping your cluster well-organized using namespaces, labels, and annotations, you’ll steer clear of all the potential performance, maintenance, and security issues that come from a lack of control over the deployed objects and services.
14. Not Adding Wildcardable Tolerations To Vital DaemonSets
Essential DaemonSets providing basic IO for pods like CNI and CSI should run on all nodes. No exceptions. Similarly, observability components are generally needed on all nodes, like the logging forwarder and APM.
Quite often, if you need to create an isolated node group – for example, VMs with special hardware like GPUs or short-lived special needs workloads like Spark jobs – these nodes will most likely get tainted. Only workloads that should be scheduled on these nodes will be scheduled there – and nothing else. You don’t want random pods to exhaust precious resources.
When this happens, some essential DaemonSets may not be able to start on these nodes due to taints (lack of toleration), and you’ll end up with a blind spot in logging coverage.
Having these two lines on all essential DaemonSets will ensure you have perfect coverage:
tolerations: operator: "Exists"
15. Running Business Logic in DaemonSets
DaemonSets are helper workloads, and in the absence of other business workloads on a node, they should not provide any services.
Sometimes, engineers add important business functionality to DaemonSet – like, on a limited set of nodes, DaemonSets would provide authentication forwarding functionality, weird anti-pod affinity through DaemonSets, or some form of horizontal scaling. Most often, that kind of implementation will lead to outages and misunderstandings.
16. Applications Unable To Terminate Gracefully in a Short Time Window
For many years, we’ve seen the trend to move away from reliable and expensive infrastructure to resilient applications. It costs way less, and the impact is much lower if applications can operate in hostile environments.
Borg (Kubernetes) was created for such cases as opportunistic scheduling, trying to do calculations on underutilized hardware but then quickly freeing up resources if more important workloads demand capacity. If something fails, retry on other hardware.
So, it would be much better if your applications could gracefully terminate in a short time window without risking data loss or corruption.
This requirement opens up much easier Kubernetes and application lifecycles, wider options on the cost optimization front, and overall much less mental overhead and stress.
Wrap Up to K8s Worst Practices
I personally saw how a lack of these best practices creates cascading issues, and I have seen it literally 100 times. Running our business-critical apps on Kubernetes doesn’t have to be painful or stressful if you embrace it fully.
Some companies use admission controllers to prevent even deploying applications to the K8s cluster if they don’t meet best practice criteria. This is good practice, by the way.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, DataOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
Ethical AI and Responsible Data Science: What Can Developers Do?
Managing Application Logs and Metrics With Elasticsearch and Kibana
The Effect of Data Storage Strategy on PostgreSQL Performance
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post