I'm From Ops, Should I Do Chaos?

I'm From Ops, Should I Do Chaos?
Chaos Engineering from the perspective of an Ops person. In this post, an Ops team member conducting chaos engineering shares the challenges and expectations.
Chaos Engineering is a useful technique to prepare the teams to respond to production issues and reduce application downtime. In this article, an Ops team member who is involved in conducting chaos engineering puts forth his/her perspective, challenges, and expectations with respect to chaos engineering. Ops in the context of this article are the team responsible for releasing software, provisioning infrastructure, managing production support, and monitoring applications in production.
I love stability. DevOps experts tell me that those days of working in silos are gone and I should collaborate with the Dev team for all ‘continuous…’ culminating in continuous production deployment. Agree, and totally.
But I love stability. I care for the customers and end-users as much as I do for newer features and innovative solution approaches. I understand that chaos engineering helps in making the applications robust and improving the efficacy of application and infra support. In fact, I would support chaos engineering to make sure that I get a handle on potential issues in servers, client machines, networks, communication devices, and the applications themselves long before they actually happen in production. After all who wouldn’t want to be prepared?
But my problem is simulating in pseudo prod or pre-prod: this only prepares me for ‘planned’ or pre=defined conditions. Though one could argue that the chaos engineering tools can pull out any services or any server or any device randomly, we tend to ‘configure’ them and in some ways get to know what could go wrong.
The maximum benefit of chaos engineering is when the tools create chaos in production, in real-time applications, and at unpredictable points in time. Now I am scared of this! I need help from my DevOps experts, BCP team, and my leadership to find answers to these questions:
a. Is my FAQ handbook rich enough to get solutions for most of the issues?
b. Are my SOPs comprehensive and well tested to be able to help me when disaster strikes?
c. How good are my BCP and DRP when a large outage happens? What would be my specific role in the coordination effort to manage the issues and get the apps back in prod?
d. How good are my tools to spot and isolate impacted services and equipment?
e. Are my prod applications categorized for criticality so that the SOPs and the recovery team could focus on the most critical apps and services?
f. Are my apps tested for security vulnerabilities? How shielded are they from the vulnerabilities?
g. Is my app security team involved in the architecture and design stage of the applications? Did they do threat modeling to build security into the application?
h. How sensitive is my app security leadership to the OWASP top threats published from time to time? Do they make a conscious effort to protect the applications from the threats that are relevant in my context?
i. Is the Ops team trained and coached to look at chaos engineering as a positive step to protect the applications and minimize disruptions rather than as an unwanted, overwhelming testing exercise?
j. Is there an approach to move from simulated pre-prod testing to real chaos testing in production? What would it take to make such a progression? Has my leadership made effort to train and coach the tech teams to build confidence in our applications and infrastructure?
k. Will I be made aware of a chaos engineering exercise at all? Ideally, I should be caught unawares and pushed to provide quick support.
l. Am I bound by the standard SLAs when a ‘new’ issue crops up because of the chaos engineering exercise? Why not – that’s part of the testing, isn’t it?
m. Do we conduct chaos engineering in an integrated manner to randomly pull down apps and infrastructure or do we conduct them in separate phases such as software services, servers, client machines, network devices, etc?
n. How is my SRE team organized – is it structured as an SRE team per platform or portfolio of applications or a separate SRE team for each application? How will the SRE teams collaborate among themselves and the Dev/architecture team during and after the chaos engineering exercise?
o. Is the IT leadership willing to review the chaos engineering practices and tools to make it easy for me in Ops and all others involved in building and maintaining the apps?
p. And what about cloud-hosted applications? Is the cloud service provider an integral part of the chaos engineering exercise?
I know that no single individual can provide answers to all these questions. I am raising these to get the different groups moving in order to address these and put a certain foundation in place for chaos engineering to succeed. This is not only for the benefit of me as an ops person but for the entire solution development and maintenance teams.
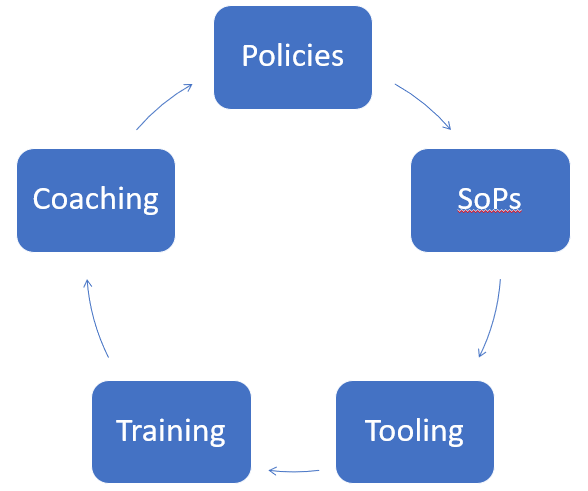
Chaos engineering is not easy, especially if it is done on production infrastructure and applications running in production. Organizations that want to embrace chaos engineering practices should start with commitment from the leadership to invest in establishing the necessary policies, standard practices, and tooling.
The managers and the technical staff in turn should mine patterns and exceptions to continuously improve the practices, tools, and guidelines. While doing this the entire IT organization should put security at the forefront to prevent inadvertent exposure of their applications and infrastructure to the attackers.
ZippyOPS Provide consulting, implementation, and management services on DevOps, DevSecOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist:
https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
Terraform AWS Three Tier Application
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post